2.
オーディオ API 原文
2.1
BaseAudioContext インターフェース 原文
このインターフェースはAudioNodeAudioDestinationNode接続 されます。
BaseAudioContextAudioContextOfflineAudioContext
enum AudioContextState {
"suspended ",
"running ",
"closed "
}; 列挙値の説明 suspended
このコンテキストは現在中断(コンテキストの時間は進まず、オーディオハードウェアはパワーダウン/解放)しています。
running
オーディオは処理状態にあります。
closed
このコンテキストは解放され、もうオーディオ処理に使用できません。全てのシステムオーディオリソースは解放されました。
新しいノードを作成しようとすると InvalidStateError が発生します。(AudioBufferは
createBuffer or
decodeAudioData を通してまだ作成できるかも知れません)
enum AudioContextPlaybackCategory {
"balanced ",
"interactive ",
"playback "
}; 列挙値の説明 balanced
オーディオ出力のレイテンシーと安定性/消費電力のバランスを取ります。
interactive
オーディオ出力のレイテンシーをグリッジが発生しない最小値にする。これがデフォルトになります。
playback
オーディオ出力のレイテンシーよりも再生の途切れを起こさない事を優先します。消費電力は最も低くなります。
dictionary AudioContextOptions {
AudioContextPlaybackCategoryplaybackCategory "interactive" ;
}; callback DecodeErrorCallback = void (DOMException error callback DecodeSuccessCallback = void (AudioBufferdecodedData Constructor(optional AudioContextOptions contextOptions) ]
interface BaseAudioContext : EventTarget {
readonly attribute AudioDestinationNodedestination
readonly attribute float sampleRate
readonly attribute double currentTime
readonly attribute AudioListenerlistener
readonly attribute AudioContextStatestate
Promise<void> suspend
Promise<void> resume
Promise<void> close
attribute EventHandler onstatechange
AudioBuffercreateBuffer unsigned long numberOfChannels unsigned long length float sampleRate
Promise<AudioBuffer decodeAudioData ArrayBuffer audioData optional DecodeSuccessCallbacksuccessCallback , optional DecodeErrorCallbackerrorCallback );
AudioBufferSourceNodecreateBufferSource
Promise<AudioWorker createAudioWorker DOMString scriptURL
ScriptProcessorNodecreateScriptProcessor optional unsigned long bufferSize = 0
, optional unsigned long numberOfInputChannels = 2
, optional unsigned long numberOfOutputChannels = 2
);
AnalyserNodecreateAnalyser
GainNodecreateGain
DelayNodecreateDelay optional double maxDelayTime = 1.0
);
BiquadFilterNodecreateBiquadFilter
IIRFilterNodecreateIIRFilter sequence<double> feedforward sequence<double> feedback
WaveShaperNodecreateWaveShaper
PannerNodecreatePanner
SpatialPannerNodecreateSpatialPanner
StereoPannerNodecreateStereoPanner
ConvolverNodecreateConvolver
ChannelSplitterNodecreateChannelSplitter optional unsigned long numberOfOutputs = 6
);
ChannelMergerNodecreateChannelMerger optional unsigned long numberOfInputs = 6
);
DynamicsCompressorNodecreateDynamicsCompressor
OscillatorNodecreateOscillator
PeriodicWavecreatePeriodicWave Float32Array real Float32Array imag optional PeriodicWaveConstraintsconstraints );
};2.1.1 属性 原文 currentTime double 型, readonly
コンテキストのレンダリンググラフで最後に処理されたオーディオブロックの最後のサンプルフレームの次のサンプルの秒で表した時刻です。もしコンテキストのレンダリンググラフがまだオーディオブロックを処理していない場合 currentTime
currentTimeBaseAudioContextOfflineAudioContext
Web Audio API の全てのスケジュールされた時刻は currentTime に対する相対値になります。
BaseAudioContextrunningcurrentTime はシステムがオーディオブロックを処理するに従って徐々に増加し、常に次に処理されるオーディオブロックの先頭の時刻を表します。それはまた現在の状態に対する変更が効力を持つ最も早い時刻でもあります。
destination AudioDestinationNode
AudioDestinationNodeAudioNode
listener AudioListener
AudioListener空間音響 で使用されます。
onstatechange EventHandler 型
BaseAudioContextEventHandler を設定するために使用されるプロパティです。新たに作成された AudioContextは 常に "suspended" 状態から開始し、状態の変化イベントは異なる状態への遷移の度に発行されます。
sampleRate float 型, readonly
BaseAudioContextAudioNode
state AudioContextState
BaseAudioContext の現在の状態を表します。コンテキストの状態は、"suspended" から開始し、システムのリソースを確保してオーディオの処理を開始した時に "running" に遷移します (MUST )。OfflineAudioContext の場合は、 startRendering() が呼び出されるまで state は "suspended" のままで、呼び出されたのちに "running" に遷移し、オーディオ処理が完了すると "close" に遷移して oncomplete (訳注:イベント) が発行されます。
state が "suspended" の時、 resume() を呼び出すと "running" に遷移し、また close() を呼び出すと "closed" に遷移します。
state が "running" の時、 suspend() を呼び出すと "suspended" に遷移し、また close() を呼び出すと "closed" に遷移します。
state が "closed" の時、これ以上の状態の遷移はできません。
2.1.2 メソッド 原文 close
オーディオコンテキストをクローズし、BaseAudioContextBaseAudioContextcurrentTime の進行を suspend し、処理を終了する事を妨げる可能性のあるシステムのオーディオリソースは強制的に開放されます。
Promise は、全てのオーディオコンテキストの作成をブロックするリソースが解放された時にリゾルブされます。もしこれが OfflineAudioContextInvalidStateError の名前の DOMException で Promise はリジェクトされます。
パラメータなし
戻り値: Promise<void>
createAnalyser
AnalyserNode
パラメータなし
createAudioWorker
AudioWorkerAudioWorkerGlobalScopeパラメータ 型 Null可 省略可 説明 scriptURL DOMString✘ ✘
このパラメータはAudioWorkerAudioWorker
createBiquadFilter
幾つかのタイプのフィルタに設定可能な2次フィルタを表す BiquadFilterNodeパラメータなし
createBuffer
与えられたサイズの AudioBuffer を作成します。バッファ内のデータは0(無音)で初期化されます。 もし、引数のどれかが負、0または範囲外の場合、NotSupportedError 例外を発生します(MUST )。
パラメータ 型 Null可 省略可 説明 numberOfChannels unsigned long✘ ✘
バッファが持つチャンネル数を指定します。 実装は少なくとも32チャンネルをサポートしなくてはなりません。
length unsigned long✘ ✘
バッファのサイズをサンプルフレーム数で指定します。
sampleRate float✘ ✘
バッファ内のリニアPCMオーディオデータのサンプルレートを秒あたりのサンプルフレーム数で表します。 実装は少なくとも8192から96000の範囲をサポートしなくてはなりません。
createBufferSource
AudioBufferSourceNodeパラメータなし
createChannelMerger
チャンネル結合器を表す ChannelMergerNodeMUST )。
パラメータ 型 Null可 省略可 説明 numberOfInputs unsigned long = 6
✘ ✔
numberOfInputs は入力の数を指定します。値は32までサポートされなくてはなりません。 もし指定されない場合は6となります。
createChannelSplitter
チャンネル分割器を表す ChannelSplitterNodeMUST )。
パラメータ 型 Null可 省略可 説明 numberOfOutputs unsigned long = 6
✘ ✔
出力の数を指定します。32までサポートされなくてはなりません。 もし指定されない場合は6となります。
createConvolver
ConvolverNodeパラメータなし
createDelay
遅延時間が可変な遅延機能を表す DelayNodeパラメータ 型 Null可 省略可 説明 maxDelayTime double = 1.0
✘ ✔
maxDelayTime パラメータはオプションであり、その遅延機能の遅延時間の最大値を秒で指定します。
もし指定する場合は、その値は0よりも大きく3分よりも小さくなければなりません(MUST )。そうでない場合 NotSupportedError 例外を発生します(MUST )。
createDynamicsCompressor
DynamicsCompressorNodeパラメータなし
createGain
GainNodeパラメータなし
createIIRFilter
一般的なIIRフィルターを表すIIRFilterNodeパラメータ 型 Null可 省略可 説明 feedforward sequence<double>✘ ✘
IIR フィルターの伝達関数のフィードフォワード(分子)の係数の配列です。
この配列の最大の長さは20です。もし全ての値が0の場合、InvalidStateError 例外を発生しますMUST 。配列の長さが0または20より大きい場合は NotSupportedError 例外を発生しますMUST 。
feedback sequence<double>✘ ✘
IIR フィルターの伝達関数のフィードバック(分母)の係数の配列です。
この配列の最大の長さは20です。もし配列の最初の要素が0の場合、InvalidStateError 例外を発生しますMUST 。もし配列の長さが0または20より大きい場合は NotSupportedError 例外を発生しますMUST 。
createOscillator
OscillatorNodeパラメータなし
createPanner
このメソッドは廃止予定で、場合に応じて createSpatialPanner または createStereoPanner で置き換えられます。
PannerNodeパラメータなし
createPeriodicWave
任意の倍音構成を表す PeriodicWavereal および imag パラメータは Float32Array ([TYPED-ARRAYS MUST )。
全ての実装は少なくとも8192までの配列の長さをサポートしなくてはなりません。
これらのパラメータは任意の周期波形を表すフーリエ級数 の係数の一部分を表します。 作成されたPeriodicWaveOscillatorNode正規化 された時間領域の波形を表現します。 別の言い方をするとこれは OscillatorNodeAPI で使用される最大振幅の信号に対応します。 PeriodicWave はデフォルトでは作成時に正規化されるため、real および imag パラメータは相対値 を表します。
もし disableNormalization パラメータによってディセーブルされていた場合、正規化は行われず、時間領域の波形はフーリエ係数で与えられた振幅を持ちます。
PeriodicWavereal および imag パラメータとして使用した配列を createPeriodicWave() 呼び出し後に変更しても PeriodicWave
パラメータ 型 Null可 省略可 説明 real Float32Array✘ ✘
real パラメータはコサイン項(慣習的な言い方でA項)の配列を表します。 オーディオの用語では最初の要素(インデックス0)は周期波形の DC オフセットとなります。 2番目の要素(インデックス1)は基本周波数を表します。3番目の要素は最初の倍音を表し、それ以降も同様に続いてゆきます。
最初の要素は無視され、実装は内部的に0に設定しなくてはなりません。
imag Float32Array✘ ✘
imag パラメータはサイン項(慣習的な言い方でB項)の配列を表します。 最初の要素(インデックス0)はフーリエ級数には存在しないため、0でなくてはなりません(これは無視されます)。 2番目の要素(インデックス1)は基本周波数を表します。3番目の要素は最初の倍音を表し、それ以降も同様に続いてゆきます。
constraints PeriodicWaveConstraints✘ ✔
もし与えられていない場合は、波形は正規化されます。そうでない場合、波形は constraints に与えられた値に従って正規化されます。
createScriptProcessor
このメソッドは廃止予定で、createAudioWorker で置き換えられます。
JavaScript を使ったオーディオデータ直接処理のための ScriptProcessorNodebufferSizenumberOfInputChannelsnumberOfOutputChannelsMUST )。
numberOfInputChannelsnumberOfOutputChannelsMUST )。
パラメータ 型 Null可 省略可 説明 bufferSize unsigned long = 0
✘ ✔
bufferSizeaudioprocess イベントが発生する頻度とそれぞれの呼び出しでどれだけのサンプルフレームを処理する必要があるかを制御します。 bufferSizeレイテンシー は低く(良く)なります。 オーディオが途切れ、グリッジ が発生する事を避けるには大きな値が必要となります。 レイテンシー とオーディオ品質の間のバランスを取るためには、プログラマはこのバッファサイズを指定せず、実装に最適なバッファサイズを選択させる事が推奨されます。
もしこのパラメータの値が上に示した許された2の累乗の値でない場合、IndexSizeError 例外を発生します(MUST )。
numberOfInputChannels unsigned long = 2
✘ ✔
このパラメータはこのノードの入力チャンネル数を指定します。32チャンネルまでの値がサポートされなくてはなりません。
numberOfOutputChannels unsigned long = 2
✘ ✔
このパラメータはこのノードの出力チャンネル数を指定します。 32チャンネルまでの値がサポートされなくてはなりません。
createSpatialPanner
SpatialPannerNodeパラメータなし
createStereoPanner
StereoPannerNodeパラメータなし
createWaveShaper
非線形な歪み効果を表すWaveShaperNodeパラメータなし
decodeAudioData
ArrayBuffer 内にあるオーディオファイルのデータを非同期にデコードします。 ArrayBuffer は、例えば XMLHttpRequest で responseType に "arraybuffer" を指定した場合の response 属性としてロードされます。
オーディオファイルデータは audio または video 要素でサポートされるどのフォーマットでも構いません。
decodeAudioData に渡されるバッファは [mimesniff
この関数の基本的なインターフェースの手段は戻り値の Promise ではありますが、歴史的な理由からコールバックのパラメータも提供されています。システムは Promise がリゾルブまたはリジェクト、またコールバック関数が呼ばれて完了する前に AudioContext
次のステップが実行されなくてはなりません:
promise を新しい Promise とします。
もし、audioData が null または正常な arrayBuffer でない場合:
error を NotSupportedError という名前の DOMException とします。
promise を error でリジェクトします。
もし、errorCallback があれば、error を持って errorCallback を呼び出します。
このアルゴリズムを終了します。
これ以降 JavaScript からアクセスや変更ができないように audioData の ArrayBuffer を無力化します。
デコード処理が別のスレッドで実行されるようにキューに登録します。
promise を返却します。
デコードスレッドで:
エンコードされている audioData をリニア PCM にデコードを試みます。
もしオーディオフォーマットが認識できない、サポートされていない、あるいはデータが破壊/不正/一貫していないという理由でデコードエラーが発生した場合、メインスレッドのイベントループで:
error を "EncodingError" という名前の DOMException とします。
promise を error を持ってリジェクトします。
もし errorCallback があれば、error を持って errorCallback を呼び出します。
それ以外の場合:
リニア PCM で表現され、もし audioData のサンプルレートが AudioContext のサンプルレートと異なっていた場合はリサンプルされたオーディオデータをデコード結果として受け取ります。
メインスレッドのイベントループで:
buffer を最終的な結果(必要ならサンプルレート変換を行った後)を保持した AudioBuffer とします。
promise を buffer を持ってリゾルブします。
もし successCallback があれば、buffer を持って successCallback を呼び出します。
パラメータ 型 Null可 省略可 説明 audioData ArrayBuffer✘ ✘
圧縮されたオーディオデータを含む ArrayBuffer です
successCallback DecodeSuccessCallback✘ ✔
デコードが完了した時に呼び出されるコールバック関数です。コールバック関数の引数は1つでデコードされた PCM オーディオデータをあらわす AudioBuffer になります。
errorCallback DecodeErrorCallback✘ ✔
オーディオファイルをデコード中にエラーが起こった場合に呼び出されるコールバック関数です。
resume
サスペンド状態にある BaseAudioContextcurrentTime の進行を再開し、フレームバッファの内容を再度送り出します。
Promise はシステムが(必要なら)オーディオハードウェアへのアクセスを再度得て、ディスティネーションへのストリーミングを開始した時、あるいは、もしコンテキストが既に実行状態なら(副作用なく)即時にリゾルブされます。
Promise はもしコンテキストがクローズされている場合
リジェクトされます。もしコンテキストが現在サスペンド状態でない場合 Promise はリゾルブされます。
このメソッドの呼び出しの後、オーディオの最初のブロックがレンダリングされるまで currentTime は変化しない事に注意してください。
パラメータなし
戻り値: Promise<void>
suspend
BaseAudioContextcurrentTime の進行をサスペンドします。現在既にディスティネーションに送り出すために処理されているブロックの処理は許可され、システムはオーディオハードウェアの使用を解放します。これは一般的にアプリケーションが BaseAudioContext
システムがサスペンドされている間、 MediaStream は出力が無視されます---つまりメディアストリームのリアルタイム性によってデータが失われる事になります。 HTMLMediaElement も同様にシステムが resume されるまで出力が無視されます。
AudioWorker と ScriptProcessorNode は単純に onaudioprocess イベントが発行されなくなりますが、resume された時には復帰します。
AnalyserNode では窓関数の目的から、データは継続的に流れているものとみなされます - つまり resume() / suspend() は AnalyserNode のデータストリームに無音状態を作りません。
パラメータなし
戻り値: Promise<void>
decodedData AudioBuffer
デコードされたオーディオデータを保持する AudioBuffer です。
error DOMException 型
デコード中に発生したエラーです。
playbackCategory AudioContextPlaybackCategory 型"interactive"
オーディオ出力のレイテンシーと消費電力のバランスに影響する再生のタイプを識別します。
2.1.6
ライフタイム 原文
AudioContext は一度作成された後、これ以上再生する音がなくなるまで、あるいはページを移動するまで再生を続けます。
2.3
OfflineAudioContext インターフェース 原文
OfflineAudioContextAudioContextAudioBuffer として戻します。
OfflineAudioContext は AudioContext.CreateBuffer と同じ引数で作成されます。
もし引数のどれかが負の値、0、あるいは範囲外であった場合は NotSupportedException 例外を発生しますMUST 。
unsigned long numberOfChannels
バッファが幾つのチャンネルを持つかを指定します。サポートされるチャンネル数については
createBuffer を参照してください。
unsigned long length
バッファのサイズをサンプルフレーム数で指定します。
float sampleRate
バッファ内のリニア PCM のオーディオデータのサンプルレートを毎秒のサンプルフレーム数で記述します。
使用できるサンプルレートについては
createBuffer を参照してください。
[Constructor(unsigned long numberOfChannels, unsigned long length, float sampleRate) ]
interface OfflineAudioContext : BaseAudioContext Promise<AudioBuffer startRendering
Promise<void> resume
Promise<void> suspend double suspendTime
attribute EventHandler oncomplete
}; 2.3.2 メソッド 原文 resume
サスペンド状態のオーディオコンテキストの進行を再開します。
OfflineAudioContextInvalidStateError でリジェクトされます。
ライブ情報を扱う AudioContextcurrentTime の値は常にオーディオグラフによって次にレンダリングされるブロックの先頭時間を指します。
パラメータなし
戻り値: Promise<void>
startRendering
与えられた現在の接続とスケジュールされたオートメーションでオーディオのレンダリングを開始します。システムは Promise がリゾルブされコールバック関数が呼び出されるまで、あるいは suspend 関数が呼び出されるまで OfflineAudioContext がガベージコレクションされない事を保証します。
オーディオデータのレンダリング結果を得る基本的なメソッドは Promise の戻り値ですが、歴史的な理由によりこのインスタンスは complete という名前のイベントも発行します。
次のステップが実行されなくてはなりません:
もし、 startRendering が既に呼ばれている場合、 Promise は InvalidStateError でリジェクトされます。
promise を新しい Promise とします。
非同期に次のステップを実行します:
このインスタンスのコンストラクタが呼ばれた時の numberOfChannels をチャンネル数、 length を長さ、 sampleRate をサンプルレートとした新しい AudioBuffer を buffer とします。
現在の接続とスケジューリングで length のサンプルフレーム数のオーディオを buffer にレンダリング開始します。
必要があればレンダリングを行うブロック毎にチェックとサスペンドを行います。
もしサスペンド状態のコンテキストが再開した場合、バッファへのレンダリングを再開します。
レンダリングが完了した時、
promise を buffer でリゾルブします。
OfflineAudioCompletionEventcomplete という名前のイベントを発行するためにキューに入れ、その renderedBuffer プロパティに buffer をセットします。
promise を戻します。
パラメータなし
suspend
オーディオコンテキストの時間の進行を指定の時刻にサスペンドする事をスケジューリングし、 Promise を返します。
これは一般的に OfflineAudioContext
サスペンドの最大の精度はレンダリング処理の分割のサイズであり、指定されたサスペンド時刻は最も近い分割の境界に丸められる事に注意してください。このため、同じ分割フレーム内に複数のサスペンドをスケジューリングする事はできません。また、スケジューリングはコンテキストが高精度のサスペンドを保証しない実行を行っている間に行わなくてはなりません。
パラメータ 型 Null可 省略可 説明 suspendTime double✘ ✘
レンダリングのサスペンドをスケジュールする時刻。これはレンダリングの分割サイズの境界に丸められます。
もし丸められた結果のフレーム数が、
負の値
現在の時刻より小さいまたは同じ
レンダリングのトータルの長さより大きいか同じ
他のサスペンドのスケジューリングと同じ時刻
の場合は、 Promise は InvalidStateError でリジェクトされます。
戻り値: Promise<void>
[Constructor ]
interface AudioContext : BaseAudioContext
2.3.3
OfflineAudioCompletionEvent インターフェース 原文
これは OfflineAudioContextEvent です。
interface OfflineAudioCompletionEvent : Event {
readonly attribute AudioBufferrenderedBuffer
}; 2.3.3.1 属性 原文 renderedBuffer AudioBuffer 型
レンダリングされたオーディオデータを保持する AudioBuffer です。
2.4
AudioNode インターフェース 原文
AudioNode は AudioContext処理グラフ を形成します。 それぞれのノードは入力 や出力 を持つ事ができます。 ソースノード は入力を持たず、単一の出力を持ちます。
AudioDestinationNodeAudioNode
それぞれの出力は1つ以上のチャンネルを持っています。正確なチャンネル数はそれぞれの AudioNode
出力は1つ以上の AudioNodeファンアウト がサポートされています。
入力は初期化時には接続されていません。しかし、1つ以上の AudioNodeファンイン がサポートされています。
AudioNodeAudioNodeconnect() メソッドが呼ばれた時、それをその入力への接続 と呼びます。
各 AudioNode入力 はその時々で特定のチャンネル数を持ちます。この数はその入力への接続 によって変化します。 もし入力が接続を持っていない場合、チャンネル数は1で無音となります。
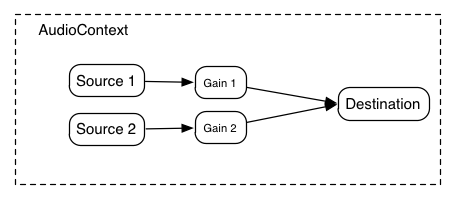
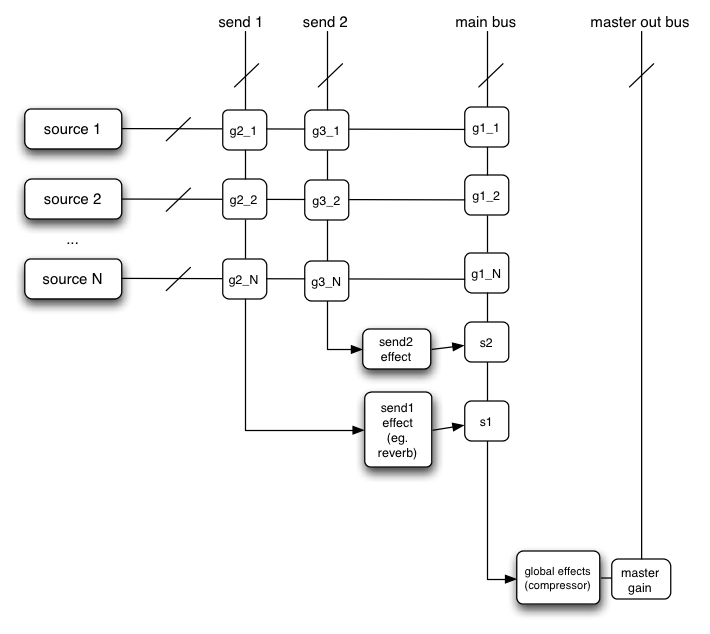
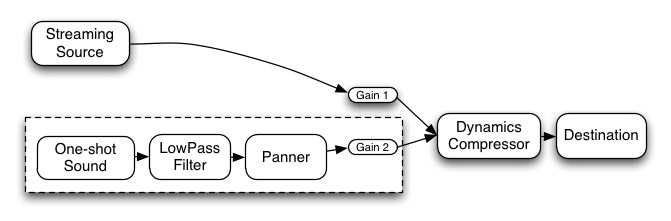
AudioNode3. ミキサーゲイン構成 5.
チャンネルのアップミックスとダウンミックス
AudioNodeAudioContextAudioDestinationNodeAudioContext
パフォーマンス的な理由から実際の実装ではそれぞれの AudioNodeブロックサイズ のサンプルフレームをブロック単位に処理する事が必要になると思われます。
実装による振る舞いを統一するため、この値を明示的に定めます。ブロックサイズ はサンプルレート44.1kHzにおいて約3msとなる128サンプルフレームとします。
AudioNode は、DOM DOM EventTarget です。 これは他の EventTarget がイベントを受け取るのと同じ方法でイベントを AudioNode
enum ChannelCountMode {
"max ",
"clamped-max ",
"explicit "
}; enum ChannelInterpretation {
"speakers ",
"discrete "
}; 列挙値の説明 speakers
モノ/ステレオ/クワッド/5.1のためのアップ・ダウンミックス式 を使用します。 チャンネル数がこれらのスピーカー基本レイアウトに一致しない場合、 "discrete" に戻します。
discrete
アップミックスの場合、チャンネルを使い切るまで順に埋めて行き、余っているチャンネルには0を出力します。 ダウンミックスでは、可能な限りチャンネルを順に埋め、余ったチャンネルは捨てられます。
interface AudioNode : EventTarget {
AudioNodeconnect AudioNodedestination optional unsigned long output = 0
, optional unsigned long input = 0
);
void connect AudioParamdestination optional unsigned long output = 0
);
void disconnect
void disconnect unsigned long output
void disconnect AudioNodedestination
void disconnect AudioNodedestination unsigned long output
void disconnect AudioNodedestination unsigned long output unsigned long input
void disconnect AudioParamdestination
void disconnect AudioParamdestination unsigned long output
readonly attribute AudioContextcontext
readonly attribute unsigned long numberOfInputs
readonly attribute unsigned long numberOfOutputs
attribute unsigned long channelCount
attribute ChannelCountModechannelCountMode
attribute ChannelInterpretationchannelInterpretation
}; 2.4.2 メソッド 原文 connect
あるノードの特定の出力から別のノードの特定の入力への接続は1つだけ存在できます。同じ端子間の複数回の接続は無視されます。例えば:
例 4
nodeA . connect ( nodeB );
nodeA . connect ( nodeB );
は次のものと同じ効果になります。
例 型 Null可 省略可 説明 destination AudioNode✘ ✘
destinationパラメータは接続先のAudioNodedestinationが他のAudioContextAudioNodeMUST )。
つまり AudioNodes は複数の AudioContext
output unsigned long = 0
✘ ✔
output パラメータは AudioNodeMUST )。
connect() を複数回呼び出して AudioNode input unsigned long = 0
✘ ✔
input パラメータは接続先の AudioNodeMUST )。
ある AudioNodeAudioNode循環 を作るような接続を行う事も可能です:
つまりある AudioNodeAudioNodeAudioNode循環 の中に少なくとも1つの DelayNodeMUST )。
connect
AudioNodeAudioParam
connect() を複数回呼び出す事で AudioNodeAudioParam
connect() を複数回呼び出す事で、複数の AudioNodeAudioParam
AudioParamAudioNodeモノに変換 します。 そして接続されている各出力をミックスし、更に最終的にパラメータが持っているタイムラインの変化スケジュールを含む固有 値( AudioParam値)とミックスします。
特定のノードの出力と特定の AudioParam
nodeA . connect ( param );
nodeA . connect ( param );
nodeA.connect(param);
パラメータ 型 Null可 省略可 説明 destination AudioParam✘ ✘
destination パラメータは接続先の AudioParam接続先の AudioParam output unsigned long = 0
✘ ✔
output パラメータは AudioNodeparameter が範囲外の場合、IndexSizeError 例外を発生します (MUST )。
戻り値: void
disconnect
AudioNode
パラメータなし
戻り値: void
disconnect
AudioNodeAudioNodeAudioParam
パラメータ 型 Null可 省略可 説明 output unsigned long✘ ✘
このパラメータは接続を切る AudioNodeMUST )。
戻り値: void
disconnect
AudioNodeAudioNode
パラメータ 型 Null可 省略可 説明 destination AudioNode✘ ✘
destination パラメータは切断する AudioNodedestination に対する全ての接続を切断します。
もしdestination に対する接続がない場合、InvalidAccessError を発生します (MUST )。
戻り値: void
disconnect
AudioNodeAudioNode
パラメータ 型 Null可 省略可 説明 destination AudioNode✘ ✘
destination パラメータは切断する AudioNodedestination への接続が存在しない場合、InvalidAccessError 例外を発生します (MUST )。
output unsigned long✘ ✘
output パラメータは接続を切る AudioNodeMUST )。
戻り値: void
disconnect
AudioNodeAudioNode
パラメータ 型 Null可 省略可 説明 destination AudioNode✘ ✘
destination パラメータは切断する AudioNodedestination の与えられた入力への接続が存在しない場合、InvalidAccessError 例外を発生します (MUST )。
output unsigned long✘ ✘
output パラメータは切断する AudioNodeMUST )。
input unsigned long✘ ✘
input パラメータは切断する接続先 AudioNodeMUST )。
戻り値: void
disconnect
特定の接続先 AudioParamAudioNodeAudioNode
パラメータ 型 Null可 省略可 説明 destination AudioParam✘ ✘
destination パラメータは切断する AudioParamdestination への接続が存在しない場合、InvalidAccessError 例外を発生します (MUST )。
戻り値: void
disconnect
AudioNodeAudioParamAudioNode
パラメータ 型 Null可 省略可 説明 destination AudioParam✘ ✘
destination パラメータは切断される AudioParamdestination への接続が存在しない場合、InvalidAccessError 例外を発生します (MUST )。
output unsigned long✘ ✘
output パラメータは切断される AudioNodeparameterが範囲外の場合、IndexSizeError 例外を発生します (MUST )。
戻り値: void
このセクションは参考情報です。
実装では、必要のないリソース利用や未使用または終了しているノードが際限なくメモリを使うのを避ける為の何らかの方法を選ぶでしょう。 以降の説明は、一般的に期待されるノードのライフタイムの管理の仕方を案内するものです。
何かしら参照される限り、AudioNode
通常 のJavaScript参照。通常のガベージコレクションのルールに従います。
AudioBufferSourceNodeOscillatorNode再生中 の参照。 再生している間これらのノードは、自分自身への再生中 参照を維持します。
接続 参照。別の AudioNode
余韻時間 参照。AudioNodeConvolverNodeAudioNode
環状に接続され、且つ直接または間接的に AudioContextAudioDestinationNodeAudioNodeAudioContext
注
AudioNode
参照を全く持たなくなった時、AudioNodeAudioNode
上記の参照の種類に関わらず、ノードの AudioContextAudioNode
2.5
AudioDestinationNode インターフェース 原文
これはユーザーが聴く事になる最終的な音の出力地点を表す AudioNodeAudioContextAudioContextAudioContextdestination 属性を介して 1つだけ存在します。
numberOfInputs : 1
numberOfOutputs : 0
channelCount = 2;
channelCountMode = "explicit";
channelInterpretation = "speakers";
interface AudioDestinationNode : AudioNode readonly attribute unsigned long maxChannelCount
};
2.6
AudioParam インターフェース 原文
AudioParamAudioNodevalue 属性を使って特定の値に即時にセットする事ができます。 あるいは(AudioContextcurrentTime 属性の時間軸で) 非常に高い時間精度で値の変化のスケジュールを組む事ができ、エンベロープ、音量のフェード、LFO、フィルタスイープ、グレイン窓、などに応用する事ができます。
このような方法で任意のタイムラインベースのオートメーション曲線をすべての AudioParamAudioNodeAudioParam固有値 に加算する事ができます。
幾つかの合成や処理の AudioNodeAudioParams 型の属性を持っています。 その他の AudioParams はサンプル単位の精度は重要ではなく、その値の変化はより粗く取り込まれます。 各 AudioParam は a-rate パラメータつまりサンプル単位で反映されるか、それ以外の k-rate パラメータかが指定されます。
実装はそれぞれの AudioNode
それぞれの 128 サンプルフレームのブロックに対して、 k-rate パラメータは最初のサンプルのタイミングで取り込まれ、その値は ブロック全体に対して使用されなくてはなりません。 a-rate パラメータはブロック内のサンプルフレーム毎に取り込まれなくてはなりません。
AudioParam は時間軸に沿ったイベントリストを保持し、その初期値は空になっています。
この時間は AudioContextcurrentTime 属性による時間軸を使用します。 イベントは時刻に対して値を割り付けるものです。
以降のメソッドはメソッド毎に固有のタイプのイベントをリストに新しく加える事でイベントリストを変更します。
それぞれのイベントは対応する時刻を持っており、リスト上で常に時刻順に保持されます。
これらのメソッドはオートメーションメソッド と呼ばれます:
これらのメソッドが呼ばれる時、次の規則が適用されます:
もし、これらのイベントを追加しようとした時、まったく同じ型のイベントが同じ時刻に既に存在している場合、新しいイベントは古いイベントを置き換えます。
もし、これらのイベントを追加しようとした時、同じ時刻に異なる型のイベントが 1 つ以上存在している場合、新しいイベントはそれら既にあるイベントの後ろで、時刻がより後ろのイベントの前に追加されます。
もし、setValueCurveAtTime() が time \(T\)、duration \(D\) で呼ばれた時、 \(T\) より後ろで \(T+D\) より手前に何らかのイベントが既に存在している場合、 NotSupportedError 例外を発生します(MUST )。 別の言い方をすると、他のイベントを含んだ期間の値のカーブをスケジュールする事はできません。
同様に、 SetValueCurve イベントの time \(T\) と duration \(D\) で示される期間内の時刻を指定して何らかのオートメーション メソッドを呼んだ場合、NotSupportedError 例外を発生します (MUST )。
interface AudioParam {
attribute float value
readonly attribute float defaultValue
AudioParamsetValueAtTime float value double startTime
AudioParamlinearRampToValueAtTime float value double endTime
AudioParamexponentialRampToValueAtTime float value double endTime
AudioParamsetTargetAtTime float target double startTime float timeConstant
AudioParamsetValueCurveAtTime Float32Array values double startTime double duration
AudioParamcancelScheduledValues double startTime
}; 2.6.1 属性 原文 defaultValue float 型, readonly
value 属性の初期値です。
value float 型
浮動小数のパラメータの値です。
この属性の初期値は defaultValue です。 もし value がオートメーションイベントが設定されている期間中に設定された場合、それは無視され、例外は発生しません。
この属性を設定した場合の効果は setValueAtTime() を現在の AudioContext の currentTime と値で呼び出すのと同じです。
それ以降のこの属性の値へのアクセスは同じ値を返します。
2.6.2 メソッド 原文 cancelScheduledValues
startTime と同じかそれ以降にスケジュールされているすべてのパラメータ変化をキャンセルします。
(与えられた時間よりも小さな startTime を指定した) アクティブな setTargetAtTime オートメーション もまたキャンセルされます。
パラメータ 型 Null可 省略可 説明 startTime double✘ ✘
開始時間が同じかそれ以降に設定されていたパラメータ変化のスケジュールをキャンセルする時刻です。
これは AudioContextcurrentTime と同じ時間軸の時刻を使用します。
もし startTime が負の値あるいは有限数でない場合 TypeError 例外を発生します (MUST )。
exponentialRampToValueAtTime
前にスケジュールされているバラメータ値から指定された値まで、指数的に連続して値を変化させる事をスケジュールします。 フィルタの周波数や再生スピードなどのパラメータは人間の聴覚特性のため、指数的変化が適しています。
時間範囲 \(T_0 \leq t < T_1\) (ここで \(T_0\) は前のイベントの時刻で \(T_1\) はこのメソッドの endTime) パラメータです) に対して次のように計算されます:
$$
v(t) = V_0 \left(\frac{V_1}{V_0}\right)^\frac{t - T_0}{T_1 - T_0}
$$
ここで \(V_0\) は時刻 \(T_0\) での値、 \(V_1\) はこのメソッドの value パラメータです。
もし \(V_0\) または \(V_1\) が真に正の値(訳注:0を含まない )でない場合はエラーとなります。
これはまた、0 に向かう指数カーブが不可能である事も示しています。
setTargetAtTime で適当な時間定数を選択する事で良い近似を得る事ができます。
もしこの ExponentialRampToValue イベント以降のイベントがない場合
\(t \geq T_1\), \(v(t) = V_1\) となります。
パラメータ 型 Null可 省略可 説明 value float✘ ✘
パラメータが指数変化により指定された時刻に到達する値です。
この値が 0 より小さいまたは 0、または前のイベントで指定された値が 0 より小さいまたは 0 の場合、NotSupportedError 例外を発生します (MUST )。
endTime double✘ ✘
AudioContextcurrentTime 属性と同じ時間軸で、指数変化が終了する時刻です。
もし endTime が負の値または有限数でない場合 TypeError 例外を発生します (MUST )。
linearRampToValueAtTime
前にスケジュールされているパラメータ値から指定された値まで、直線的に連続して値を変化させる事をスケジュールします。
時間範囲 \(T_0 \leq t < T_1\) (ここで \(T_0\) は前のイベントの時刻、 \(T_1\) はこのメソッドで指定された endTime です) の間の値は次のように計算されます:
$$
v(t) = V_0 + (V_1 - V_0) \frac{t - T_0}{T_1 - T_0}
$$
ここで \(V_0\) は時刻 \(T_0\) での値、 \(V_1\) はこのメソッドで指定された value です。
もしこの LinearRampToValue イベント以降にイベントがない場合、 \(t \geq T_1\), \(v(t) = V_1\) となります。
パラメータ 型 Null可 省略可 説明 value float✘ ✘
与えられた時刻にパラメータが直線変化で到達する値です。
endTime double✘ ✘
AudioContextcurrentTime 属性と同じ時間軸で、オートメーション終了する時刻です。
もし endTime が負の値または有限数でない場合 TypeError 例外を発生します (MUST )。
setTargetAtTime
指定の時間から、指定の時定数によって指数的に目標の値に漸近を開始します。 様々な使い方がありますが、これはADSRエンベロープの"ディケイ"および"リリース"を実装する際に役立ちます。 値は指定の時間に即、目標値になるのではなく徐々に目標値に向かって変化する事に注意してください。
時間範囲 : \(T_0 \leq t < T_1\) 、ここで \(T_0\) は startTime パラメータの時刻、
\(T_1\) はこのイベントに続くイベントの時刻 (あるいは次のイベントがない場合は \(\infty\) ) として:
$$
v(t) = V_1 + (V_0 - V_1)\, e^{-\left(\frac{t - T_0}{\tau}\right)}
$$
ここで、 \(V_0\) は初期値 (\(T_0\) での .value属性の値)、\(V_1\) は target パラメータの値、そして \(\tau\) は timeConstant パラメータです。
パラメータ 型 Null可 省略可 説明 target float✘ ✘
パラメータが指定の時刻から変化を開始 する目標値です。
startTime double✘ ✘
AudioContextcurrentTime 属性と同じ時間軸で指数的漸近を開始する時刻です。
もし start が負の値または有限数でない場合は TypeError 例外を発生します (MUST )。
timeConstant float✘ ✘
目標値に漸近する一次フィルター (指数) の時定数の値です。
この値が大きいと変化はゆっくりになります。値は真に正の値(訳注: 0 を含まない )でなくてはなりません。そうでない場合 TypeError 例外を発生します (MUST )。
より正確には、timeConstant は一次の線形時不変系でステップ応答(0 から 1 への変化) に対して \(1 - 1/e\) (約 63.2%) となる時間を指します。
setValueAtTime
指定の時刻になるとパラメータ値を変更するようにスケジュールします。
もしこの SetValue イベントの後にもうイベントがない場合、 \(t \geq T_0\) に対して \(v(t) = V\) ここで \(T_0\) は startTime 、そして \(V\) は value パラメータの値です。
別の言い方をすれば、値は定数のまま保持されます。
もしこの SetValue イベントの次のイベント ( 時刻は \(T_1\) ) が LinearRampToValue または ExponentialRampToValue でない場合、 \(T_0 \leq t < T_1\) に対して:
$$
v(t) = V
$$
別の言い方をすれば、値に "ステップ" を作ってこの期間定数のまま保持されます。
もしこの SetValue イベントに続く次のイベントが LinearRampToValue または ExponentialRampToValue の場合、
linearRampToValueAtTime
exponentialRampToValueAtTime
パラメータ 型 Null可 省略可 説明 value float✘ ✘
指定の時刻にパラメータが変化する値です。
startTime double✘ ✘
AudioContextcurrentTime 属性と同じ時間軸で与えられた値に変化する時刻です。
もし startTime が負の値または有限数でない場合は TypeError 例外を発生します (MUST )。
setValueCurveAtTime
指定の時刻と期間に対して、任意の値の配列を設定します。
値の個数は必要とされる期間に合うようにスケーリングされます。
\(T_0\) を startTime 、 \(T_D\) を duration 、 \(V\) を values 配列、
\(N\) を values 配列の長さとします。
期間 \(T_0 \le t < T_0 + T_D\) の間次のようになります
$$
\begin{align*} k &= \left\lfloor \frac{N - 1}{T_D}(t-T_0) \right\rfloor \\
\end{align*}
$$
そして、 \(v(t)\) は \(V[k]\) と \(V[k+1]\) の間で直線補間されます。
曲線の期間が終了した後、 (\(t \ge T_0 + T_D\)) に対して値は(もしあれば)別のオートメーションイベントまで、最後の曲線の値を保持します。
パラメータ 型 Null可 省略可 説明 values Float32Array✘ ✘
パラメータ値の曲線を表す Float32Array です。
これらの値は与えられた時刻から始まる期間に割り当てられます。
このメソッドが呼び出された時、オートメーションのために曲線の内部的なコピーが作成されます。
そのため、それ以降に渡した配列の中身を変更しても AudioParam startTime double✘ ✘
AudioContextcurrentTime 属性と同じ時間軸の曲線の適用を開始する時刻です。
もし startTime が負の値または有限数でない場合 TypeError 例外を発生します (MUST )。
duration double✘ ✘
( time (訳注:startTime )以降の) 秒で表される期間の長さであり、 この期間、値は values パラメータに従って計算されます。
2.6.3
値の計算 原文
computedValue はオーディオDSPを制御する最終的な値であり、オーディオレンダリングスレッドがそれぞれのレンダリング時刻に計算します。 内部的には次のように計算されなくてはなりません:
value 属性に直接設定されるか、あらかじめ、またはこの時刻に値の変化スケジュールが設定(オートメーションイベント)されていればこれらのイベントから固有 の値が計算されます。 もし、オートメーションイベントがスケジュールされた後に value 属性が設定された場合、これらのイベントは削除されます。 value 属性を読みだした場合は常に現在の固有の値を返します。 もしオートメーションイベントが与えられた期間から削除された場合、 固有 の値は value 属性が直接設定されるか、その期間を対象にオートメーションイベントが追加されるまで、直前の値を保持したままになります。
AudioParamAudioNodeモノに変換 し、他の同様に接続されている出力とミックスします。 もし AudioNodecomputedValue には影響を及ぼしません。
computedValue は固有 の値と(2)で計算された値の和となります。
2.6.4
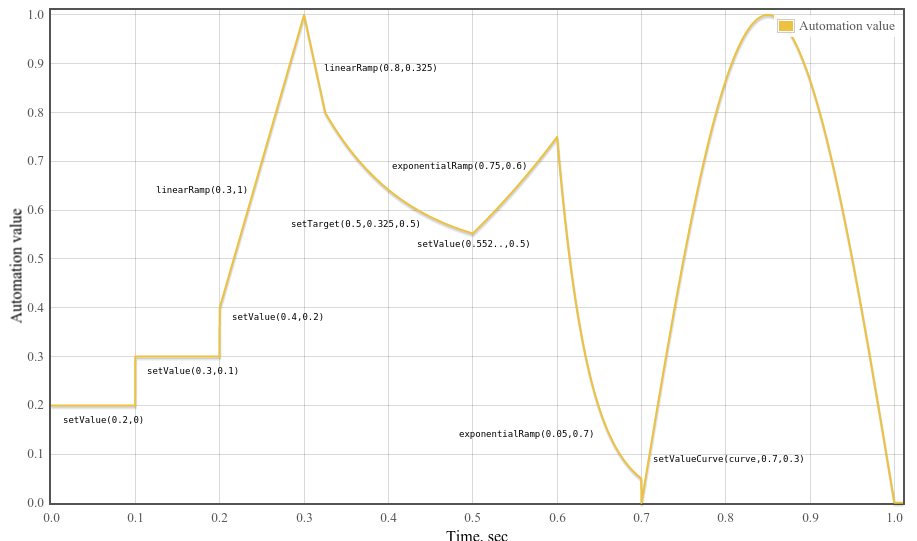
AudioParam オートメーションの例 原文
図. 4
パラメータオートメーションの例
例 6
var curveLength = 44100 ;
var curve = new Float32Array ( curveLength );
for ( var i = 0 ; i < curveLength ; ++ i )
curve [ i ] = Math . sin ( Math . PI * i / curveLength );
var t0 = 0 ;
var t1 = 0.1 ;
var t2 = 0.2 ;
var t3 = 0.3 ;
var t4 = 0.325 ;
var t5 = 0.5 ;
var t6 = 0.6 ;
var t7 = 0.7 ;
var t8 = 1.0 ;
var timeConstant = 0.1 ;
param . setValueAtTime ( 0.2 , t0 );
param . setValueAtTime ( 0.3 , t1 );
param . setValueAtTime ( 0.4 , t2 );
param . linearRampToValueAtTime ( 1 , t3 );
param . linearRampToValueAtTime ( 0.8 , t4 );
param . setTargetAtTime (. 5 , t4 , timeConstant );
// Compute where the setTargetAtTime will be at time t5 so we can make
// the following exponential start at the right point so there's no
// jump discontinuity. From the spec, we have
// v(t) = 0.5 + (0.8 - 0.5)*exp(-(t-t4)/timeConstant)
// Thus v(t5) = 0.5 + (0.8 - 0.5)*exp(-(t5-t4)/timeConstant)
param . setValueAtTime ( 0.5 + ( 0.8 - 0.5 )* Math . exp (-( t5 - t4 )/ timeConstant ), t5 );
param . exponentialRampToValueAtTime ( 0.75 , t6 );
param . exponentialRampToValueAtTime ( 0.05 , t7 );
param . setValueCurveAtTime ( curve , t7 , t8 - t7 );
2.7
GainNode インターフェース 原文
オーディオ信号のゲインを変える事はオーディオアプリケーションでは基本的な処理です。 GainNode はミキサー の構成ブロックの1つとなります。 このインターフェースは1つの信号入力と1つの信号出力を持つ AudioNode
numberOfInputs : 1
numberOfOutputs : 1
channelCountMode = "max";
channelInterpretation = "speakers";
GainNodegainAudioParamcomputedValue が乗じられます (MUST )。
interface GainNode : AudioNode readonly attribute AudioParamgain
}; 2.7.1 属性 原文 gain AudioParam
適用されるゲインの量を表します。デフォルトの value は1です(ゲイン変更なし)。名目上の minValue は 0 ですが、位相反転のために負の値に設定する事もできます。 名目上の maxValue は1ですが (例外が発生する事なく) より大きな値を設定する事もできます。このパラメータは a-rate です。
2.8
DelayNode インターフェース 原文
ディレイ機能はオーディオアプリケーションの基本的な構成要素です。このインターフェースは単一の入力と単一の出力を持つ AudioNode
numberOfInputs : 1
numberOfOutputs : 1
channelCountMode = "max";
channelInterpretation = "speakers";
出力のチャンネル数は常に入力のチャンネル数と同じになります。
これは入力されるオーディオ信号を一定の量だけ遅延させます。 具体的には各時刻 t において、入力信号 input(t) に対して、遅延時間 delayTime(t) 、出力信号 output(t) とすると 出力は output(t) = input(t - delayTime(t)) となります。 デフォルトの delayTime は0秒(遅延なし)です。
DelayNode
interface DelayNode : AudioNode readonly attribute AudioParamdelayTime
}; 2.8.1 属性 原文 delayTime AudioParam
適用する遅延(単位は秒)の量を表すAudioParam値は 0 (遅延なし) です。
最小の値は 0 で最大の値は AudioContext の createDelay メソッドの引数、 maxDelayTime で決定されます。
もし DelayNode循環 の一部になっている場合、delayTime 属性の最小値は 128 フレーム (1ブロック)にクランプされます。
このパラメータは a-rate です。
2.9
AudioBuffer インターフェース 原文
このインターフェースはメモリ上に保持されるオーディオのリソース(ワンショットの音やその他の短いオーディオクリップ)を表します。 そのフォーマットは-1 ~ +1の名目上の範囲を持つ非インターリーブのIEEE 32ビット・リニアPCMです。
1つ以上のチャンネルを持つ事ができます。
典型的には、そのPCMデータは適度に(通常1分以内程度に)短いと見込まれます。 音楽の1曲分のような長時間の音に関しては audio 要素と MediaElementAudioSourceNode によるストリーミングを使うべきです。
AudioBufferAudioContextOfflineAudioContextAudioContext
interface AudioBuffer {
readonly attribute float sampleRate
readonly attribute long length
readonly attribute double duration
readonly attribute long numberOfChannels
Float32Array getChannelData unsigned long channel
void copyFromChannel Float32Array destination unsigned long channelNumber optional unsigned long startInChannel = 0
);
void copyToChannel Float32Array source unsigned long channelNumber optional unsigned long startInChannel = 0
);
}; 2.9.1 属性 原文 duration double 型, readonly
PCM オーディオデータの秒で表現された長さです。
length long 型, readonly
PCM オーディオデータのサンプルフレーム数で表現された長さです。
numberOfChannels long 型, readonly
オーディオのチャンネル数です。
sampleRate float 型, readonly
PCM オーディオデータの秒あたりのサンプル数で表現されたサンプルレートです。
2.9.2 メソッド 原文 copyFromChannel
copyFromChannel メソッドは AudioBufferdestination で示される配列にサンプルをコピーします。
パラメータ 型 Null可 省略可 説明 destination Float32Array✘ ✘
チャンネルデータをコピーする先の配列です。
channelNumber unsigned long✘ ✘
データをコピーするチャンネルのインデックスです。
もし channelNumber が AudioBufferIndexSizeError 例外を発生します (MUST )。
startInChannel unsigned long = 0
✘ ✔
オプションのオフセットで、コピーをどこから行うかを指定します。もし startInChannel が AudioBufferlength より大きい場合、IndexSizeError 例外を発生します (MUST )。
戻り値: void
copyToChannel
copyToChannel メソッドは source で示される配列から AudioBufferパラメータ 型 Null可 省略可 説明 source Float32Array✘ ✘
チャンネルデータをコピーする元の配列です。
channelNumber unsigned long✘ ✘
データをコピーする先のチャンネルのインデックスです。もし、 channelNumber が AudioBufferIndexSizeError 例外を発生します (MUST )。
startInChannel unsigned long = 0
✘ ✔
オプションのオフセットで、コピーをどこへ行うかを指定します。もし startInChannel が AudioBufferlength より大きい場合、IndexSizeError 例外を発生します (MUST )。
戻り値: void
getChannelData
指定のチャンネルの PCM オーディオデータが格納された Float32Array を返します。
パラメータ 型 Null可 省略可 説明 channel unsigned long✘ ✘
このパラメータはデータを取得するチャンネルのインデックスです。
インデックス値0は最初のチャンネルを表します。
このインデックスは numberOfChannels より小さくなくてはならず(MUST )、そうでない場合 IndexSizeError 例外を発生します(MUST )。
戻り値: Float32Array
注
copyToChannel および copyFromChannel メソッドは より大きな配列に対する view である Float32Array を渡す事で配列の一部だけを埋める事ができます。
AudioBuffergetChannelData を呼び出して結果の配列にアクセスするよりも 不必要なメモリー割り当てとコピーを避けられるため、copyFromChannel を使用するべきです。
API の実装が AudioBuffer「AudioBuffer の内容の取得」 の内部処理が起動されます。
この処理は呼び出し元に変更不能なチャンネルデータを返します。
AudioBuffer「AudioBuffer の内容の取得」 処理は次のステップで実行されます:
もし AudioBufferArrayBuffer のどれかが無力化されている場合はこれらのステップを中止し、長さ 0 のチャンネルデータを呼び出し元に返します。
この AudioBuffergetChannelData によって返されている全ての ArrayBuffer を無力化します。
それらの ArrayBuffer の下層のデータバッファを保持して、呼び出し元(訳注:API の実装側 )に参照を返します。
次回の getChannelData の呼び出しでは、
データのコピーを持っている ArrayBuffer を AudioBuffer
「AudioBuffer の内容の取得」 処理は以下の場合に呼び出されます:
2.10
AudioBufferSourceNode インターフェース 原文
このインターフェースは AudioBuffer によってメモリ上に保持されているオーディオデータからのオーディオソースを表します。
これはオーディオデータの再生に高度なスケジューリングの柔軟性が要求される場合、例えば完全なリズムを刻むように再生する、ような場合に役立ちます。
もしネットワークからあるいはディスクからのデータをサンプル精度で再生する必要がある場合、実装する人は再生のために AudioWorker
start() メソッドはいつ再生されるかをスケジュールするために使用されます。
start() メソッドを複数回呼び出す事はできません。
再生は(もし loop 属性が指定されていなければ)バッファのオーディオデータがすべて再生されると自動的に、 あるいは stop() メソッドが呼び出されて指定された時刻になると停止します。
numberOfInputs : 0
numberOfOutputs : 1
出力のチャンネル数は常に .buffer 属性に指定された AudioBuffer のチャンネル数と同じになります。 もし .buffer が NULL の場合、チャンネルは無音の1チャンネルとなります。
interface AudioBufferSourceNode : AudioNode attribute AudioBufferbuffer
readonly attribute AudioParamplaybackRate
readonly attribute AudioParamdetune
attribute boolean loop
attribute double loopStart
attribute double loopEnd
void start optional double when = 0
, optional double offset = 0
, optional double duration );
void stop optional double when = 0
);
attribute EventHandler onended
}; 2.10.1 属性 原文 buffer AudioBuffer
再生されるオーディオのリソースを指定します。この属性は1回のみ設定できます。そうでない場合は InvalidStateError 例外を発生します (MUST )。
detune AudioParam
オーディオストリームをレンダリングするスピードを変調する追加のパラメータです。
このデフォルト値は 0 です。名目上の範囲は [-1200; 1200] になります。
このパラメータは k-rate です。
loop boolean 型
オーディオデータをループ再生する事を指定します。デフォルト値は false です。
もし loop が再生の途中で動的に変更された場合、新しい値は次のオーディオ処理ブロックで効果が表れます。
loopEnd double 型
loop 属性が true の場合、ループの終了位置を秒で表すオプションの値です。
この値はループの設定にのみ使用されます:
ループを構成するサンプルフレームは
loopStart から loopEnd-(1.0/sampleRate)となります。
デフォルト値は 0 で、通常は 0 からバッファの長さの任意の値に設定されます。
loopEnd が 0 より小さい場合ループは 0 で終了します。
もし、loopEnd がバッファの長さよりも大きい場合、ループはバッファの最後で終了します。
この属性は、バッファのサンプルレートと乗算され、最も近い整数値に丸められる事でバッファ中の正確なサンプルフレームのオフセットに変換されます。そのため動作は playbackRate loopStart double 型
loop 属性が true の場合、ループの開始位置を秒で表すオプションの値です。
デフォルト値は 0 で、通常は 0 からバッファの長さの任意の値に設定されます。
もし loopStart が 0 より小さい場合、ループは 0 から開始します。
もし loopEnd がバッファの長さよりも大きい場合、ループはバッファの最後から開始します。
この属性は、バッファのサンプルレートと乗算され、最も近い整数値に丸められる事でバッファ中の正確なサンプルフレームのオフセットに変換されます。
そのため動作は playbackRate onended EventHandler 型
AudioBufferSourceNode
HTML HTML EventHandlerを設定するための属性です。
AudioBufferSourceNodeHTML HTML Event がイベントハンドラにディスパッチされます。
playbackRate AudioParam
オーディオストリームの再生速度です。デフォルトの value は 1 です。このパラメータはk-rate です。
2.10.2 メソッド 原文 start
指定の時刻に音の再生開始をスケジュールします。
start は1回のみ呼びだす事ができ、呼び出すのは stop が呼ばれる前でなくてはなりません。
そうでない場合、InvalidStateError 例外を発生します (MUST )。
パラメータ 型 Null可 省略可 説明 when double = 0
✘ ✔
when パラメータは、再生の開始時刻を(秒で)指定します。 これは AudioContextcurrentTime 属性と同じ時間軸の時刻を使用します。 もしこの値に 0 、あるいは currentTime よりも小さな値を渡した場合、音は即時に再生されます。
もし when が負の値の場合、TypeError 例外を発生します (MUST )。
offset double = 0
✘ ✔
offset パラメータはバッファ中の再生開始位置を(秒で)指定します。
もしこの値に 0 が渡された場合、再生はバッファの先頭から開始されます。
もし offset が負の値の場合 TypeError 例外を発生します (MUST )。
もし offset が loopEnd より大きい場合、再生は loopEnd から始まり (そして即時に loopStart にループし) ます。
このパラメータはバッファのサンプルレートと乗算され、最も近い整数値に丸められる事でバッファ中の正確なサンプルフレームのオフセットに変換されます。
そのため動作は playbackRate duration double✘ ✔
duration パラメータは再生される部分の長さを(秒で)指定します。 もしこの値が渡されなかった場合、再生の長さは AudioBuffer 全体の長さから offset を引いたものになります。
つまり、offset も duration も指定されなかった場合、暗黙的に duration は AudioBuffer 全体の長さとなります。
もし duration が負の値の場合、TypeError 例外を発生します (MUST )。
戻り値: void
stop
指定の時刻に再生停止をスケジュールします。
パラメータ 型 Null可 省略可 説明 when double = 0
✘ ✔
when パラメータは、再生の停止時刻を(秒で)指定します。 これは AudioContextcurrentTime 属性と同じ時間軸の時刻を使用します。 もしこの値に 0 、あるいは currentTime よりも小さな値を渡した場合、音は即時に停止されます。
もし when が負の値の場合、TypeError 例外を発生します (MUST )。
もし stop が一度呼ばれた後に再度呼ばれた場合、呼び出しの前に既にバッファが停止しているのでなければ、最後の呼び出しのみが適用されて以前の呼び出しで設定された停止時刻は適用されません。
もしバッファが既に停止している時に更に stop を呼び出しても効果はありません。もしスケジュールされている開始時刻より前に停止時刻に到達した場合、再生は開始されません。
戻り値: void
playbackRate および detune はどちらも k-rate パラメータであり、共に computedPlaybackRate の計算に使用されます。
computedPlaybackRate ( t ) = playbackRate ( t ) * pow ( 2 , detune ( t ) / 1200 )
computedPlaybackRate はこの AudioBufferSourceNodeAudioBufferMUST )。
これは入力データを 1 / computedPlaybackRate の率でリサンプリングし、音高と速度を変化させるように実装しなくてはなりません (MUST )。
2.10.3
ループ再生 原文
もし start() が呼ばれた時に loop 属性が true であれば、再生は stop() が呼ばれて停止時刻になるまで無限に継続します。
これを "ループ" モードと呼びます。 再生は常に start() の offset 引数で指定されたバッファ中の位置から開始され、ループ モード中、 actualLoopEnd のバッファ位置 (あるいはバッファの終端位置) まで再生され、 actualLoopStart のバッファ位置に戻る事が繰り返されます。
ループ モードでは実際の ループ位置は loopStart および loopStart 属性から次のように計算されます:
if (( loopStart || loopEnd ) && loopStart >= 0 && loopEnd > 0 && loopStart < loopEnd ) {
actualLoopStart = loopStart ;
actualLoopEnd = min ( loopEnd , buffer . duration );
} else {
actualLoopStart = 0 ;
actualLoopEnd = buffer . duration ;
}
loopStart および loopEnd のデフォルト値はどちらも 0 である事に注意が必要です。これはループがバッファの先頭から始まり、バッファの終端位置で終わる事を意味します。
低レベルの実装の詳細では、特定のサンプルレート (通常は AudioContext
start() と stop() メソッドを使用して再生の開始と停止をスケジュールした時、結果的に開始または停止の時間は AudioContextMUST )。
それはつまり、サブフレームでのスケジューリングは不可能である事を意味します。
このインターフェースは audio または video 要素からの音声ソースを表します。
numberOfInputs : 0
numberOfOutputs : 1
出力のチャンネル数は HTMLMediaElement で参照されるメディアのチャンネル数に対応します。 そのため、メディア要素の .src 属性を変更する事によって、このノードの出力チャンネル数が変化します。 もし .src 属性が設定されていない場合、出力は 1 チャンネルの無音となります。
interface MediaElementAudioSourceNode : AudioNode
MediaElementAudioSourceNodeHTMLMediaElement からAudioContextcreateMediaElementSource() メソッドを使用して作成されます。
出力は1つでチャンネル数は createMediaElementSource() の引数として渡された HTMLMediaElement のオーディオのチャンネル数と同じになります。 もしその HTMLMediaElement がオーディオを持っていない場合、1となります。
HTMLMediaElement は MediaElementAudioSourceNodeMediaElementAudioSourceNode除けば 、MediaElementAudioSourceNodeを使わない場合と全く同じように振る舞わなくてはなりません。
つまり、ポーズ、シーク、ボリューム、 src 属性の変更、その他 HTMLMediaElement としての見掛けは MediaElementAudioSourceNodeいない 場合と同様に通常どおり働かなくてはなりません。
例 7
var mediaElement = document . getElementById ( 'mediaElementID' );
var sourceNode = context . createMediaElementSource ( mediaElement );
sourceNode . connect ( filterNode );
2.12
AudioWorker インターフェース 原文
AudioWorker オブジェクトは Javascript でオーディオを処理するワーカー"スレッド"のメインスレッドでの表現です。
この AudioWorker オブジェクトは同じタイプの複数のオーディオノードを作成するのに使用されるファクトリになっています。
つまりこれによりコード、プログラムデータ、グローバルな状態をノードをまたいで共有する事が簡単にできます。
AudioWorker はその AudioWorker で処理される個別のノードのメインスレッドでの表現である AudioWorkerNode
これらのメインスレッドオブジェクトはオーディオスレッドでのコンテキストの処理をインスタンス化します。
全ての AudioWorkerNode のオーディオ処理はオーディオ処理スレッド内で実行されます。
これは特に注意すべき幾つかの副作用を持っています:
オーディオワーカーのスレッドをブロックすると音のグリッジが発生し、(グリッジが起こる可能性を下げるために)もしオーディオ処理スレッドの優先度を上げるなら(ユーザーが供給するスクリプトコードのスレッド優先度の上昇の連鎖を避けるため)通常のスレッドの優先度を格下げしなくてはなりません。
オーディオワーカースクリプトの内部からは、オーディオワーカーのファクトリはノードのコンテキストの情報を表す AudioWorkerGlobalScopeAudioWorkerNodeProcessor
加えて、同じ AudioWorkerAudioWorkerNodeAudioWorkerGlobalScope
interface AudioWorker : Worker {
void terminate
void postMessage any message optional sequence<Transferable> transfer );
readonly attribute AudioWorkerParamDescriptorparameters
attribute EventHandler onmessage
attribute EventHandler onloaded
AudioWorkerNodecreateNode int numberOfInputs int numberOfOutputs
AudioParamaddParameter DOMString name float defaultValue
void removeParameter DOMString name
}; 2.12.1 属性 原文 onloaded EventHandler 型
onloaded ハンドラーはスクリプトの読み込みに成功した後に呼び出され、AudioWorkerGlobalScope
onmessage EventHandler 型
onmessage ハンドラーは AudioWorkerGlobalScope
parameters array of AudioWorkerParamDescriptor
この配列はこの AudioWorker で作成されたノードの現在の各パラメータのディスクリプタを保持しています。
これにより、AudioWorker のユーザーは簡単に AudioParam の名前とデフォルト値に対する繰り返し処理を行う事ができます。
2.12.2 メソッド 原文 addParameter
この AudioWorkerAudioWorkerNodeAudioParamAudioProcessEventparameters オブジェクトに名前に対応したリードオンリーの Float32Array を付加します。
AudioParam は即時にそのスケジューリングメソッドが呼び出されたり、 .value に値を設定されたり、あるいは AudioNode
name パラメータはそのリードオンリーの AudioParam を AudioWorkerNode に追加する際に使用され、また、以降の AudioProcessEventparameters オブジェクトでのリードオンリー Float32Array の名前として使用されます。
defaultValueAudioParam
パラメータ 型 Null可 省略可 説明 name DOMString✘ ✘ defaultValue float✘ ✘
createNode
オーディオワーカー内でノードのインスタンスを作成します。
パラメータ 型 Null可 省略可 説明 numberOfInputs int✘ ✘ numberOfOutputs int✘ ✘
postMessage
postMessage は [Workers AudioWorkerGlobalScopeパラメータ 型 Null可 省略可 説明 message any✘ ✘ transfer sequence<Transferable>✘ ✔
戻り値: void
removeParameter
この AudioWorkerAudioWorkerGlobalScopeAudioWorkerNodename の名前を持つパラメータを削除します。
またこれは名前の付いたリードオンリーの AudioParamAudioWorkerNodeAudioProcessEventparameters メンバーからその名前の付いたリードオンリーの Float32Array を 削除します。
この AudioWorker
name は削除するパラメータを指定します。
パラメータ 型 Null可 省略可 説明 name DOMString✘ ✘
戻り値: void
terminate
terminate() メソッドが呼び出された時、 AudioWorkerGlobalScopeAudioProcessEventパラメータなし
戻り値: void
AudioWorkerNodeaddParameter メソッドによって追加されたそれぞれの名前に対応したリードオンリーの AudioParam オブジェクトを持っている事に注意してください。これは動的に行われるため、IDL 表現には含まれていません。
AudioWorkerWorker から継承されるため、オーディオワーカースクリプトとの通信のために Worker のインターフェースを実装しなくてはなりません。
2.12.3
AudioWorkerNode インターフェース 原文
このインターフェースはオーディオを直接生成、処理、分析する Worker スレッドに対して作用する AudioNode
Web Audio の実装は通常オーディオ処理スレッドの優先度をノーマルよりも高くするのが普通である事に注意してください。(ユーザースクリプトはノーマルよりも高い優先度で動作させる事ができないため) AudioWokerNode の利用はオーディオ処理スレッドの優先度を格下げする場合があります。
numberOfInputs : variable
numberOfOutputs : variable
channelCount = numberOfInputChannels;
channelCountMode = "explicit";
channelInterpretation = "speakers";
createAudioWorkerNode()(訳注:createNode()の間違いと思われます ) の呼び出しの際に指定された入力と出力のチャンネルの数が初期状態の入出力のチャンネル数(および入出力それぞれに対応して AudioWorkerGlobalScopenumberOfInputChannelsnumberOfOutputChannels
使用例:
var bitcrusherFactory = context . createAudioWorker ( "bitcrusher.js" );
var bitcrusherNode = bitcrusherFactory . createNode (); interface AudioWorkerNode : AudioNode void postMessage any message optional sequence<Transferable> transfer );
attribute EventHandler onmessage
}; 2.12.3.1 属性 原文 onmessage EventHandler 型
onmessage ハンドラーは AudioWorkerNodeProcessor がメインスレッドに対してノードメッセージを送り返した際に常に呼び出されます。
2.12.3.2 メソッド 原文 postMessage
postMessage は AudioWorkerNodeProcessor に対して the
Worker specification で定義されたアルゴリズムでメッセージを送るために呼び出されます。
これは AudioWorkerGlobalScope に影響を与えるため、AudioWorker 自身で postMessage() を呼び出すのとは異なる事に注意してください。
パラメータ 型 Null可 省略可 説明 message any✘ ✘ transfer sequence<Transferable>✘ ✔
戻り値: void
AudioWorkerNodeaddParameter メソッドによって追加された名前付きパラメータ毎に対応したリードオンリーの AudioParam オブジェクトを持っている事に注意してください。これは動的に行われるため、IDL には表現されていません。
2.12.4
AudioWorkerParamDescriptor インターフェース 原文
このインターフェースは AudioWorkerNodeのAudioParam -- 端的にはその名前とデフォルト値を表します。これは (AudioParamのインスタンスを保持していない) AudioWorkerGlobalScope から AudioParam に対する反復処理を行いやすくします。
interface AudioWorkerParamDescriptor {
readonly attribute DOMString name
readonly attribute float defaultValue
}; 2.12.4.1 属性 原文 defaultValue of type float , readonly
AudioParam のデフォルト値です。
name DOMString 型, readonly
AudioParamの名前です。
2.12.5
AudioWorkerGlobalScope インターフェース 原文
このインターフェースは DedicatedWorkerGlobalScope の派生オブジェクトでオーディオ処理スクリプトが実行されるコンテキストを表します -- そしてそれはオーディオノードの複数のインスタンスで共有され、ワーカースレッド内の JavaScript を用いてオーディオの直接的な合成、処理、分析ができるように設計されています。
これはノードが例えばコンポリューションノードのように大量の共有データを持つ場合に役立ちます。
-
AudioWorkerGlobalScopeaudioprocess イベントを管理します。
- audioprocess訳注:このあたりはまだ完全な文書にはなっていないようです )
interface AudioWorkerGlobalScope : DedicatedWorkerGlobalScope {
readonly attribute float sampleRate
AudioParamaddParameter DOMString name float defaultValue
void removeParameter DOMString name
attribute EventHandler onaudioprocess
attribute EventHandler onnodecreate
readonly attribute AudioWorkerParamDescriptorparameters
}; 2.12.5.2 メソッド 原文 addParameter
このファクトリによって作成される(既に存在するあるいは今後作成される)全ての AudioWorkerNodeAudioParamAudioProcessEventparameters オブジェクトに名前に応じたリードオンリーの Float32Array を付加します。
オーディオワーカーに対してメインスレッドまたはワーカースクリプトのどちらからでも AudioParam が追加(あるいは削除)できる事は意図的なものです。
これは瞬時にワーカーベースのノードとそのプロトタイプの作成する事を可能にするだけでなく、
AudioParam の構成も単一のスクリプトに含んだワーカー全体のパッケージ化も可能にします。
ワーカースクリプトがノードを構成できるように AudioWorkerNode の oninitialized が呼び出された後でのみノードが使用される事が推奨されます。
name パラメータは
AudioWorkerNode に追加されるリードオンリーの AudioParam の名前として、また以降の AudioProcessEventparameters オブジェクト上に現れるリードオンリーの Float32Array の名前として使用される。
defaultValue パラメータは
AudioParam
パラメータ 型 Null可 省略可 説明 name DOMString✘ ✘ defaultValue float✘ ✘
removeParameter
このファクトリで作成されたノードから以前に追加された name の名前を持つパラメータを削除します。
またこれはこの名前を持つリードオンリーの AudioParamAudioWorkerNodeAudioProcessEventparameters のメンバーから削除します。 このノードにその名前のパラメーターが存在しない場合、NotFoundError 例外を発生します(MUST )。
nameは削除するパラメータを特定します。
パラメータ 型 Null可 省略可 説明 name DOMString✘ ✘
戻り値: void
2.12.6
AudioWorkerNodeProcessor インターフェース 原文
このインターフェースをサポートするオブジェクトは AudioWorkerGlobalScopeAudioWorkerGlobalScope
interface AudioWorkerNodeProcessor : EventTarget {
void postMessage any message optional sequence<Transferable> transfer );
attribute EventHandler onmessage
}; 2.12.6.1 属性 原文 onmessage EventHandler 型
onmessage ハンドラーは AudioWorkerNode がノードメッセージをオーディオスレッドに送り返す度に呼び出されます。
2.12.6.2 メソッド 原文 postMessage
postMesasge は the
Worker specification で定義されるアルゴリズムを使って AudioWorkerNode にメッセージを送るために呼び出されます。
これは AudioWorker 自身で PostMesage() を呼び出すのとは異なり、AudioWorkerGlobalScope にディスパッチされる事に注意してください。
パラメータ 型 Null可 省略可 説明 message any✘ ✘ transfer sequence<Transferable>✘ ✔
戻り値: void
2.14
AudioWorkerNodeCreationEvent インターフェース 原文
これは新しいノードオブジェクトが作成された時に AudioWorkerGlobalScopeEventオブジェクトです。
これにより、 AudioWorkerは ノード・ローカルな (例えばディレイを割り当てたり、ローカル変数を初期化する等の) データの初期化ができます。
interface AudioWorkerNodeCreationEvent : Event {
readonly attribute AudioWorkerNodeProcessornode
readonly attribute Array inputs
readonly attribute Array outputs
}; 2.14.1 属性 原文 inputs Array 型, readonly
入力の channelCount の配列です。
node AudioWorkerNodeProcessor
新しく作成されたノードです。全てのノードローカルなデータストレージ (例えば、ディレイノードのバッファ等) はこのオブジェクト上に作成されなくてはなりません。
outputs Array 型, readonly
出力の channelCount の配列です。
2.15
AudioProcessEvent インターフェース 原文
これは処理を実行するために AudioWorkerGlobalScopeEvent オブジェクトです。
イベントハンドラーは(もしあれば) inputBuffers 属性からオーディオデータにアクセスし、入力からのオーディオを処理します。
処理結果の (あるいは入力を使わずに合成された) オーディオデータは outputBuffers に格納されます。
interface AudioProcessEvent : Event {
readonly attribute double playbackTime
readonly attribute AudioWorkerNodeProcessornode
readonly attribute Float32Array[][] inputs
readonly attribute Float32Array[][] outputs
readonly attribute object parameters
}; 2.15.1 属性 原文 inputs array of array of Float32Array 型, readonly
リードオンリーの Float32Array の配列の配列です。トップレベルの配列は入力をまとめたものです。
それぞれの入力は複数のチャンネルを持っている場合があります。それぞれのチャンネルは Float32Array のサンプルデータを保持しています。
チャンネル配列の初期サイズは createAudioWorkerNode() メソッドでその入力に指定されたチャンネル数で決定されます。
しかしながら、 onprocess ハンドラーは動的に入力のチャンネル数を変更できます。あるいは ブロック長 (128) の Float32Array を追加したり、配列を (Array.lenth を減らしたり Array.pop() や Array.slice() を使用して) 減少させる事もできます。
処理システムはメモリーの動きを最小化するためにイベントオブジェクト、配列、 Float32Array を再利用します。
入力の配列の並べ替えを行っても以降のイベントでのチャンネルとの関係として認識されません。
node AudioWorkerNodeProcessor
この処理イベントがディスパッチされるノードです。全てのノードローカルなデータストレージ (例えばディレイノードのバッファ等) はこのオブジェクト上で維持されなくてはなりません。
outputs array of array of Float32Array 型, readonly
リードオンリーの Float32Array の配列の配列です。トップレベルの配列は出力をまとめたものです。
それぞれの出力は複数のチャンネルを持っている場合があります。それぞれのチャンネルは Float32Array のサンプルデータを保持しています。
チャンネル配列の初期サイズは createAudioWorkerNode() メソッドでその出力に指定されたチャンネル数で決定されます。
しかしながら、 onprocess ハンドラーは動的に入力のチャンネル数を変更できます。あるいは ブロック長 (128) の Float32Array を追加したり、配列を (Array.lenth を減らしたり Array.pop() や Array.slice() を使用して) 減少させる事もできます。
処理システムはメモリーの動きを最小化するためにイベントオブジェクト、配列、 Float32Array を再利用します。
出力の配列の並べ替えを行っても以降のイベントでのチャンネルとの関係として認識されません。
parameters object 型, readonly
addParameter で追加されたそれぞれのパラメータに対応して、名前に対応づけられたリードオンリーの Float32Array を持つ属性を表すオブジェクトです。
これは動的に処理されるため IDL には表現されません。
Float32Array の長さは inputBuffer の長さに対応します。
この Float32Array の内容は時間に対応した各点での AudioParam の値として使用されます。この Float32Array はオーディオエンジンによって再利用される事が期待されます。
playbackTime double 型, readonly
このイベントで処理されるオーディオのブロックの開始時刻です。
定義としては、これはコントロールスレッド側で読み取れる最も最近の BaseAudioContextcurrentTime 属性と同じです。
2.17
PannerNode インターフェース 原文
このインターフェースは入力されるオーディオストリームの3D空間での 定位 / 空間音響 を処理するためのノードを表します。 空間音響は AudioContextAudioListenerlistener 属性) に関連して処理されます。
numberOfInputs : 1
numberOfOutputs : 1
channelCount = 2;
channelCountMode = "clamped-max";
channelInterpretation = "speakers";
このノードの入力はモノ (1 チャンネル) またはステレオ (2 チャンネル) となり、増やす事はできません。
より少ない、または多いチャンネル数のノードからの接続は適宜アップミックスまたはダウンミックス されますが、もし、 channelCount を 2 以上に設定しようとしたり channelCountMode を "max" に設定しようとすると NotSupportedError 例外を発生します (MUST )。
このノードの出力はステレオ (2 チャンネル) にハードコードされており、変える事はできません。
PanningModelType"equalpower"です。
enum PanningModelType {
"equalpower ",
"HRTF "
}; 列挙値の説明 equalpower
単純で効率的な空間音響アルゴリズムで、等価パワーによるパンニングを行います。
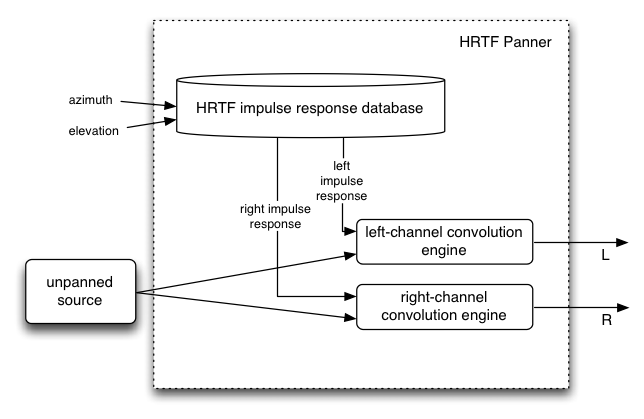
HRTF
高品質な空間音響アルゴリズムで、人体を使ったインパルスレスポンス測定からのコンボリューション処理を使用します。 このパンニング方法はステレオ出力にレンダリングされます。
DistanceModelType
次のそれぞれの距離モデルの説明で、 \(d\) はリスナーとパンナーの距離、
\(d_{ref}\) は refDistance 属性の値、
\(d_{max}\) は maxDistance 属性の値、
\(f\) は rolloffFactor の値です。
enum DistanceModelType {
"linear ",
"inverse ",
"exponential "
}; 列挙値の説明 linear
distanceGain を次のように計算する直線距離モデルです:
$$
1 - f\frac{\max(\min(d, d_{max}), d_{ref}) - d_{ref}}{d_{max} - d_{ref}}
$$
ここで \(d\) は \([d_{ref},\, d_{max}]\) の範囲に制限されます。
inverse
distanceGain を次のように計算する逆数距離モデルです:
$$
\frac{d_{ref}}{d_{ref} + f (\max(d, d_{ref}) - d_{ref})}
$$
ここで \(d\) は\([d_{ref},\,\infty)\)の範囲に制限されます。
exponential
distanceGain を次のように計算する指数距離モデルです:
$$
\left(\frac{\max(d, d_{ref})}{d_{ref}}\right)^{-f}
$$
ここで \(d\) は \([d_{ref},\,\infty)\) の範囲に制限されます。
interface PannerNode : AudioNode attribute PanningModelTypepanningModel
void setPosition float x float y float z
void setOrientation float x float y float z
void setVelocity float x float y float z
attribute DistanceModelTypedistanceModel
attribute float refDistance
attribute float maxDistance
attribute float rolloffFactor
attribute float coneInnerAngle
attribute float coneOuterAngle
attribute float coneOuterGain
}; 2.17.1 属性 原文 coneInnerAngle float 型
音源の指向性パラメータで、度で表す角度です。この角度の内部では音量減衰が生じません。
デフォルトの値は 360 で、値は 360 の剰余で扱われます。
coneOuterAngle float 型
音源の指向性パラメータで度で表す角度です。
この角度の外側では音量の減衰率が定数値の coneOuterGain となります。
デフォルトの値は360で、値は 360 の剰余で扱われます。
coneOuterGain float 型
音源の指向性パラメータで、角度が coneOuterAngle の外側の場合の減衰率です。
デフォルトの値は0です。
これは (dBでなく) リニア値で [0, 1] の範囲になります。
もしこのパラメータがこの範囲外の場合、 InvalidStateError 例外を発生します (MUST )。
distanceModel DistanceModelType
この PannerNode"inverse" です。
maxDistance float 型
音源とリスナー間の最大距離で、これ以上音源とリスナー間が離れても音量が減衰しません。
デフォルトの値は10000です。
panningModel PanningModelType
この PannerNode"equalpower" です。
refDistance float 型
音源がリスナーから離れていった時の音量減衰の基準となる距離です。
デフォルトの値は 1 です。
rolloffFactor float 型
音源がリスナーが離れていった時の音量減衰の速さを表します。
デフォルトの値は 1 です。
2.17.2 メソッド 原文 setOrientation
3D 空間のデカルト座標系で音源の向いている方向を表します。
音がどれくらいの指向性 ( cone 属性で制御されます) を持っているかによって音が リスナーからはずれると小さくなったり全く聴こえなくなったりします。
x, y, z パラメータは 3D 空間内での方向を表します。
デフォルトの値は (1, 0, 0) です。
パラメータ 型 Null可 省略可 説明 x float✘ ✘ y float✘ ✘ z float✘ ✘
戻り値: void
setPosition
listener 属性に相対する音源の位置を設定します。
3D のデカルト座標系が使用されます。
x, y, z パラメータは 3D 空間中の座標を表します
デフォルトの値は (1, 0, 0) です。
パラメータ 型 Null可 省略可 説明 x float✘ ✘ y float✘ ✘ z float✘ ✘
戻り値: void
setVelocity
音源の速度ベクトルを設定します。
このベクトルは 3D 空間内での移動する方向と速度の両方を制御します。 この速度とリスナーの速度の相対値によってどれくらいのドップラー効果 (ピッチの変化) が適用されるかが決定します。 このベクトルの単位はメートル / 秒 で、位置や方向ベクトルで使われる単位とは独立しています。
x, y, z パラメータは移動の方向と大きさを表すベクトルです。
デフォルトの値は (0, 0, 0) です。
パラメータ 型 Null可 省略可 説明 x float✘ ✘ y float✘ ✘ z float✘ ✘
戻り値: void
2.18
AudioListener インターフェース 原文
このインターフェースは廃止予定です。
これは SpatialListenerPannerNodeBaseAudioContextlistener との相対関係により空間処理されます。
空間処理の詳細については 空間配置 / バンニング セクション を参照してください。
interface AudioListener {
void setPosition float x float y float z
void setOrientation float x float y float z float xUp float yUp float zUp
}; 2.18.1 メソッド 原文 setOrientation
3D デカルト座標空間でリスナーが向いている方向を表します。
front ベクトルと up ベクトルの両方が与えられます。 簡単のため人間について言えば、front ベクトルはその人の鼻が向いている方向を表します。 up ベクトルはその人の頭頂向いている方向です。 これらは線形独立 (互いに直角) の関係になります。 これらの値がどのように解釈されるかの基準としての要件は空間配置 / バンニング セクション を参照してください。
x, y, z パラメータは 3D 空間中の front 方向ベクトルであり、デフォルトの値は (0, 0, -1) です。
xUp, yUp, zUp パラメータは 3D 空間中の up 方向ベクトルであり、デフォルトの値は (0, 1, 0) です。
パラメータ 型 Null可 省略可 説明 x float✘ ✘ y float✘ ✘ z float✘ ✘ xUp float✘ ✘ yUp float✘ ✘ zUp float✘ ✘
戻り値: void
setPosition
3D デカルト座標空間でのリスナーの位置を設定します。
PannerNode
x, y, z パラメータは 3D 空間内の座標を表します。
デフォルトの値は (0, 0, 0) です。
パラメータ 型 Null可 省略可 説明 x float✘ ✘ y float✘ ✘ z float✘ ✘
戻り値: void
2.19
SpatialPannerNode インターフェース 原文
このインターフェースは入力されるオーディオストリームを 3D 空間内に定位 させる処理を行うノードを表します。空間定位は AudioContextSpatialListenerlistener 属性)との関係で行われます。
この空間定位の音響効果は、SpatialPanner が直接 destination ノードに接続されていないとうまく動作しない事を明らかにしなくてはなりません。つまり、以降に続く(SpatialPannerの後ろでdestinationより手前の) 処理は効果を妨害する可能性があります。
numberOfInputs : 1
numberOfOutputs : 1
channelCount = 2;
channelCountMode = "clamped-max";
channelInterpretation = "speakers";
このノードへの入力はモノ (1チャンネル) またはステレオ (2チャンネル) のどちらかで、増やす事はできません。より多くのチャンネルを持つノードからの接続は適宜アップミックスまたはダウンミックス されますが、channelCount を2以上、あるいは channelCountMode を "max" に設定しようとすると NotSupportedError 例外を発生します (MUST )。 このノードの出力はステレオ (2チャンネル) であり今のところ構成を変える事はできません。
PanningModelType"equal-power"です。
enum PanningModelType {
"equalpower ",
"HRTF "
}; 列挙値の説明 equalpower
equal-powerバンニングで使用されるシンプルで効率的な空間配置アルゴリズムです。
HRTF
より高品位の空間配置アルゴリズムで人体のインパルスレスポンスの測定からのコンボリューションを使用します。この定位方法はステレオ出力をレンダリングします。
DistanceModelType
enum DistanceModelType {
"linear ",
"inverse ",
"exponential "
}; 列挙値の説明 linear
distanceGain を次のように計算する直線距離モデルです:
1 - rolloffFactor * (distance - refDistance) / (maxDistance - refDistance)
inverse
distanceGain を次のように計算する逆数距離モデルです:
refDistance / (refDistance + rolloffFactor * (distance - refDistance))
exponential
distanceGain を次のように計算する指数距離モデルです:
pow(distance / refDistance, -rolloffFactor)
interface SpatialPannerNode : AudioNode attribute PanningModelTypepanningModel
readonly attribute AudioParampositionX
readonly attribute AudioParampositionY
readonly attribute AudioParampositionZ
readonly attribute AudioParamorientationX
readonly attribute AudioParamorientationY
readonly attribute AudioParamorientationZ
attribute DistanceModelTypedistanceModel
attribute float refDistance
attribute float maxDistance
attribute float rolloffFactor
attribute float coneInnerAngle
attribute float coneOuterAngle
attribute float coneOuterGain
}; 2.19.1 属性 原文 coneInnerAngle float 型
音源の指向性パラメータで、度で表す角度です。この角度の内部では音量減衰が生じません。 デフォルトの値は360です。
coneOuterAngle float 型
音源の指向性パラメータで、度で表す角度です。この角度の外側では音量の減衰率が定数値の coneOuterGain となります。 デフォルトの値は360です。
coneOuterGain float 型
音源の指向性パラメータで、角度が coneOuterAngle よりも外側の場合の音量の減衰率です。 デフォルトの値は0です。
distanceModel DistanceModelType
この PannerNode訳注:SpatialPannerNode ) で使用される距離モデルを指定します。デフォルトは "inverse" です。
maxDistance float 型
音源とリスナーの最大距離で、これ以上これ以上音源とリスナー間が離れても音量が減衰しません。 デフォルトの値は10000です。
orientationX AudioParam
orientationX、 orientationY、 orientationZパラメータは 3D 空間内での方向を表します。
orientationY AudioParam
3D 空間のデカルト座標で音源が向いている方向ベクトルの y 成分を表します。デフォルトは 0 です。このパラメータは a-rate です。
orientationZ AudioParam
3D 空間のデカルト座標で音源が向いている方向ベクトルの Z 成分を表します。デフォルトは 0 です。このパラメータは a-rate です。
panningModel PanningModelType
この PannerNode訳注:SpatialPannerNode ) で使用される定位モデルを指定します。デフォルトは "equal-power" です。
positionX AudioParam
3D 空間のデカルト座標で音源の位置のx座標を指定します。デフォルトは 0 です。このパラメータは a-rate です。
positionY AudioParam
3D 空間のデカルト座標で音源の位置の y 座標を指定します。デフォルトは 0 です。このパラメータは a-rate です。
positionZ AudioParam
3D 空間のデカルト座標で音源の位置の z 座標を指定します。デフォルトは 0 です。このパラメータは a-rate です。
refDistance float 型
音源がリスナーから離れていった時の音量減衰のリファレンスとなる基準距離です。 デフォルトの値は 1 です。
rolloffFactor float 型
音源がリスナーが離れていった時の音量減衰の速さを表します。 デフォルトの値は1です。
2.20
SpatialListener インターフェース 原文
このインターフェースは人がオーディオシーンを聴く位置と方向を表します。
全ての SpatialPannerNodeAudioContextspatialListenerとの関係で空間音響処理を行います。
空間音響についての詳細は 空間音響/定位 セクション を参照してください。
interface SpatialListener {
readonly attribute AudioParampositionX
readonly attribute AudioParampositionY
readonly attribute AudioParampositionZ
readonly attribute AudioParamforwardX
readonly attribute AudioParamforwardY
readonly attribute AudioParamforwardZ
readonly attribute AudioParamupX
readonly attribute AudioParamupY
readonly attribute AudioParamupZ
}; 2.20.1 属性 原文 forwardX AudioParam
forwardX, forwardY, forwardZ パラメータは 3D 空間内のベクトルを表します。
forward ベクトルと up ベクトルはリスナーの方向を決定します。
簡単に人間についての言葉で言えば、forward ベクトルは人の鼻が指している方向です。
up ベクトルは人の頭頂が指している方向になります。
これらの値は(お互いに直角であり)線形独立と期待され、そうでなければ予期できない結果をもたらします。
これらの値をどのように解釈するかの基準要件については、空間音響セクション を参照してください。
forwardY AudioParam
3D デカルト空間でリスナーが向いている方向の y 成分を表します。デフォルトは 0 です。このパラメータは a-rate です。
forwardZ AudioParam
3D デカルト空間でリスナーが向いている方向の z 成分を表します。デフォルトは 0 です。このパラメータは a-rate です。
positionX AudioParam
3D デカルト空間でリスナーの位置の x 座標を表します。SpatialPannerNode positionY AudioParam
3D デカルト空間でリスナーの位置の y 座標を表します。デフォルト値は 0 です。このパラメータは a-rate です。
positionZ AudioParam
3D デカルト空間でリスナーの位置の z 座標を表します。デフォルト値は 0 です。このパラメータは a-rate です。
upX AudioParam
upX, upY, upZ パラメータは 3D 空間でのリスナーの "up" 方向を指示する方向ベクトルを表します。
この値がどのように解釈されるかの基準要件については、空間音響セクション を参照してください。
upY span class="idlAttrType">AudioParam
3D デカルト空間でリスナーの up 方向の y 成分を表します。デフォルト値は 0 です。このパラメータは a-rate です。
upZ AudioParam
3D デカルト空間でリスナーの up 方向の z 成分を表します。デフォルト値は 0 です。このパラメータは a-rate です。
2.21
StereoPannerNode インターフェース 原文
入力されるオーディオストリームに対してローコストなイコールパワー・バンニング アルゴリズムによりステレオでの定位処理を行うノードを表します。このバンニング効果はステレオストリームでの定位を行う方法として一般的なものです。
numberOfInputs : 1
numberOfOutputs : 1
channelCount = 2;
channelCountMode = "clamped-max";
channelInterpretation = "speakers";
このノードの入力はステレオ(2チャンネル)であり増やす事はできません。より少ない、あるいは多いチャンネル数のノードから接続された場合は適宜チャンネル・アップミックスまたはダウン・ミックス されますが、もしchannelCountを2より大きな値に設定しようとする、あるいはchannelCountModeを"max"に設定しようとすると NotSupportedError 例外を発生します。
このノードの出力はステレオ(2チャンネル)にハードコードされており、構成を変える事はできません。
interface StereoPannerNode : AudioNode readonly attribute AudioParampan
}; 2.21.1 属性 原文 pan AudioParam
出力されるステレオイメージ中での入力信号の位置を指定します。-1ならば完全な左、+1ならば完全な右になります。デフォルト値は0で、範囲は-1から+1となります。このパラメータは a-rate です。
2.22
ConvolverNode インターフェース 原文
このインターフェースはインパルスレスポンスによって線形コンボリューションエフェクトを 適用する処理ノードを表すインターフェースです。
numberOfInputs : 1
numberOfOutputs : 1
channelCount = 2;
channelCountMode = "clamped-max";
channelInterpretation = "speakers";
このノードの入力はモノ (1 チャンネル) またはステレオ (2 チャンネル) であり増やす事はできません。
より少ないチャンネル数または多いチャンネル数のノードからの接続は、適宜アップミックスまたはダウンミックス されますが、channelCount を 2 以上の値、あるいは channelCountMode を "max" に設定しようとすると NotSupportedError 例外を発生します (MUST )。
interface ConvolverNode : AudioNode attribute AudioBufferbuffer
attribute boolean normalize
}; 2.22.1 属性 原文 buffer AudioBuffer
ConvolverNodeAudioBufferAudioBuffer は 1、2、または 4チャンネルでなくてはならずそうでない場合は NotSupportedError 例外を発生します (MUST )。
この AudioBufferAudioContextMUST )。
この属性が設定される際に、buffer と normalize 属性によってこのインパルスレスポンスが与えられた正規化の後、ConvolverNode normalize boolean 型
buffer 属性がセットされた時に等価パワーで正規化してインパルスレスポンスをスケーリングされるかどうかを制御します。
このデフォルトの値は true で、様々なインパルスレスポンスをロードした時にコンボルバーからの出力レベルを均一化するようになっています。
もし normalize が false に設定された場合、インパルスレスポンスの前処理/スケーリングなしでコンボリューションが行われます。 この値を変更した場合、次回に buffer 属性をセットするまで効果は現れません。
もし buffer 属性が設定された時に normalize 属性が false の場合 ConvolverNodebuffer 内のインパルスレスポンスをそのまま使用して線形コンボリューションを行います。
そうでなく、buffer 属性を設定した時に normalize 属性が true であれば、ConvolverNodebuffer 内のデータのスケールドRMS-パワー解析を行い、normalizationScale を計算します:
function calculateNormalizationScale ( buffer )
{
var GainCalibration = 0.00125 ;
var GainCalibrationSampleRate = 44100 ;
var MinPower = 0.000125 ;
// Normalize by RMS power.
var numberOfChannels = buffer . numberOfChannels ;
var length = buffer . length ;
var power = 0 ;
for ( var i = 0 ; i < numberOfChannels ; i ++) {
var channelPower = 0 ;
var channelData = buffer . getChannelData ( i );
for ( var j = 0 ; j < length ; j ++) {
var sample = channelData [ j ];
channelPower += sample * sample ;
}
power += channelPower ;
}
power = Math . sqrt ( power / ( numberOfChannels * length ));
// Protect against accidental overload.
if (! isFinite ( power ) || isNaN ( power ) || power < MinPower )
power = MinPower ;
var scale = 1 / power ;
// Calibrate to make perceived volume same as unprocessed.
scale *= GainCalibration ;
// Scale depends on sample-rate.
if ( buffer . sampleRate )
scale *= GainCalibrationSampleRate / buffer . sampleRate ;
// True-stereo compensation.
if ( numberOfChannels == 4 )
scale *= 0.5 ;
return scale ;
}
処理の間 ConvolverNode はこの計算された normalizationScale 値を 最終出力を得るために入力と( buffer で表される)インパルスレスポンスを処理した線形コンボリューションの結果と掛け合わせます。 あるいは、例えば入力に事前に normalizationScale をかけ合わせたり、normalizationScale を掛け合わせたバージョンのインパルスレスポンスを作るなど、 何らかの数学的に等価な演算が使用されるかも知れません。
2.22.2
入力、インパルスレスポンス、出力のチャンネル構成 原文
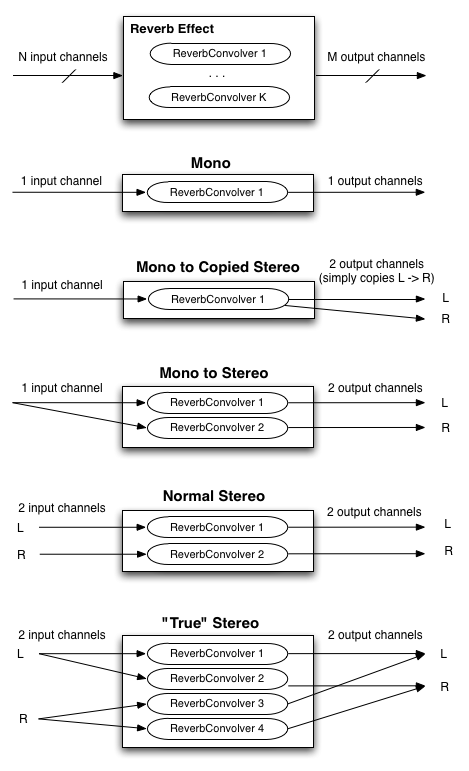
実装は 1 または 2 チャンネルの入力に対する様々なリバーブエフェクトを実現するために次のような ConvolverNodeMUST )。
図示されている最初の図は一般的なケースで、音源が N 個の入力チャンネル、インパルスレスポンスは K 個のチャンネル、再生システムは M 個の出力チャンネルを持っています。
ConvolverNode
単一チャンネルのコンポリューションはモノラルオーディオ入力に対してモノラルインパルスレスポンスを使用してモノラル出力を得ます。
残りの図はモノラルおよびステレオ再生で N と M は 1 または 2、 K は 1 または 2 または 4 の場合です。
開発者がより複雑で任意のマトリックスを必要とするなら ChannelSplitterNodeConvolverNodeChannelMergerNode
図. 5
ConvolverNode
2.23
AnalyserNode インターフェース 原文
このインターフェースはリアルタイムの周波数および時間領域の分析を可能にするノードを表します。
オーディオストリームは加工されずに入力から出力に渡されます。
numberOfInputs : 1
numberOfOutputs : 1 この出力は接続されずに放置される事もある事に注意してください。
channelCount = 1;
channelCountMode = "max";
channelInterpretation = "speakers";
interface AnalyserNode : AudioNode void getFloatFrequencyData Float32Array array
void getByteFrequencyData Uint8Array array
void getFloatTimeDomainData Float32Array array
void getByteTimeDomainData Uint8Array array
attribute unsigned long fftSize
readonly attribute unsigned long frequencyBinCount
attribute float minDecibels
attribute float maxDecibels
attribute float smoothingTimeConstant
}; 2.23.1 属性 原文 fftSize of type unsigned long
周波数領域の分析に使用するFFTのサイズです。これは32から32768までの2の累乗でなくてはならず、そうでなければ、IndexSizeError例外を発生します (MUST )。
デフォルトの値は2048です。大きなFFTサイズは計算量が増加する事に注意してください。
frequencyBinCount unsigned long 型, readonly
FFTサイズの1/2の値です。
maxDecibels float 型
maxDecibels は FFT 解析データを unsigned byte 値へ変換するスケーリングの際の最大パワー値です。 デフォルトの値は -30 です。 もしこの属性の値が minDecibels MUST )。
minDecibels float 型
minDecibels は FFT 解析データを unsigned byte値へ変換するスケーリングの際の最少パワー値です。 デフォルトの値は -100 です。 もしこの属性の値が maxDecibels MUST )。
smoothingTimeConstant float 型
0 -> 1 の範囲の値で、0ならば最後の解析フレームに対して時間平均が取られない事を表します。 デフォルトの値は0.8です。 もしこの属性の値が0より小さいか1より大きい値が設定された場合、IndexSizeError 例外を発生します(MUST )。
2.23.2 メソッド 原文 getByteFrequencyData
現在の周波数データ を渡された unsigned byte 配列にコピーします。 もし配列が frequencyBinCount よりも小さい場合、余った要素は捨てられます。もし配列が frequencyBinCount よりも大きい場合、余剰の要素は無視されます。
unsigned byte 配列に格納される値は次のように計算されます。
FFT 窓関数とスムージング で説明されているように \(Y[k]\) を現在の周波数データ とします。
バイトの値は、
$$
b[k] = \frac{255}{\mbox{dB}_{max} - \mbox{dB}_{min}}
\left(Y[k] - \mbox{dB}_{min}\right)
$$
ここで、\(\mbox{dB}_{min}\) は minDecibels maxDecibels
パラメータ 型 Null可 省略可 説明 array Uint8Array✘ ✘
このパラメータは周波数領域の分析データをコピーする場所を示します。
戻り値: void
getByteTimeDomainData
現在のダウンミックスされた時間領域(波形)データを渡された unsigned byte 配列にコピーします。 もし、配列が fftSize よりも小さい場合、余った要素は捨てられます。 もし配列が fftSize よりも多くの要素を持つ場合、余剰の要素は無視されます。
unsigned byte 配列に格納される値は次のように計算されます。
\(x[k]\) を時間領域データとします。バイトの値、\(b[k]\) は、
$$
b[k] = 128(1 + x[k]).
$$
もし \(b[k]\) が 0 から 255 の範囲外の場合、\(b[k]\) は範囲内にクリップされます。
パラメータ 型 Null可 省略可 説明 array Uint8Array✘ ✘
このパラメータは時間領域のサンプルデータをコピーする場所を示します。
戻り値: void
getFloatFrequencyData
現在の周波数データ を渡された浮動小数配列にコピーします。 もし配列が frequencyBinCount よりも小さい場合、余った要素は捨てられます。もし配列が frequencyBinCount よりも大きい場合、余剰の要素は無視されます。
周波数データの単位はdBです。
パラメータ 型 Null可 省略可 説明 array Float32Array✘ ✘
このパラメータは周波数領域の分析データをコピーする場所を示します。
戻り値: void
getFloatTimeDomainData
現在のダウンミックスされた時間領域(波形)データを渡された浮動小数配列にコピーします。もし配列が fftSize よりも小さい場合、余った要素は捨てられます。もし配列が fftSize よりも大きい場合、余剰の要素は無視されます。
パラメータ 型 Null可 省略可 説明 array Float32Array✘ ✘
このパラメータは時間領域のサンプルデータをコピーする場所を示します。
戻り値: void
2.23.3
FFT 窓関数と時間的スムージング 原文
現在の周波数データ が計算された時、次の処理が行われます:
時間領域の入力の全てのチャンネルをモノにダウンミックスします
時間領域の入力データにブラックマン窓 を適用します
窓関数を通した時間領域の入力データからイマジナリとリアルの周波数データを得るため、フーリエ変換 を適用します
周波数領域データに時間的スムージング の処理を行います
dBへの変換を行います .
次の式では \(N\) をこの AnalyserNode の .fftSize 属性とします
ブラックマン窓の適用 は時間領域の入力に対して次の処理を行います。
\(n = 0, \ldots, N - 1\) に対する \(x[n]\) は時間領域のデータです。
$$
\begin{align*}
\alpha &= \mbox{0.16} \\ a_0 &= \frac{1-\alpha}{2} \\
a_1 &= \frac{1}{2} \\
a_2 &= \frac{\alpha}{2} \\
w[n] &= a_0 - a_1 \cos\frac{2\pi n}{N} + a_2 \cos\frac{4\pi n}{N}, \mbox{ for } n = 0, \ldots, N - 1
\end{align*}
$$
窓関数を通した信号 \(\hat{x}[n]\) は
$$
\hat{x}[n] = x[n] w[n], \mbox{ for } n = 0, \ldots, N - 1
$$
フーリエ変換の適用 は次のようなフーリエ変換の計算から成ります。
\(X[k]\) は周波数領域の複素数データで \(\hat{x}[n]\) は上で計算された窓関数を通した時間領域のデータです。そして、
$$
X[k] = \sum_{n = 0}^{N - 1} \hat{x}[n] e^{\frac{-2\pi i k n}{N}}
$$
ただし \(k = 0, \dots, N/2-1\)
周波数データの時間軸のスムージング は次のように処理されます:
そしてスムージングされた値、\(\hat{X}[k]\) は次の式で計算されます
$$
\hat{X}[k] = \tau\, \hat{X}_{-1}[k] + (1 - \tau)\, |X[k]|
$$
ただし \(k = 0, \ldots, N - 1\)
dBへの変換 は次の処理で行われます。
\(\hat{X}[k]\) を時間的スムージング で計算された値として:
$$
Y[k] = 20\log_{10}\hat{X}[k]
$$
ただし \(k = 0, \ldots, N-1\)
この配列、\(Y[k]\) は getFloatFrequencyData によって出力の配列にコピーされます。
getByteFrequencyData に対しては、\(Y[k]\) は minDecibels maxDecibels minDecibels maxDecibels
2.24
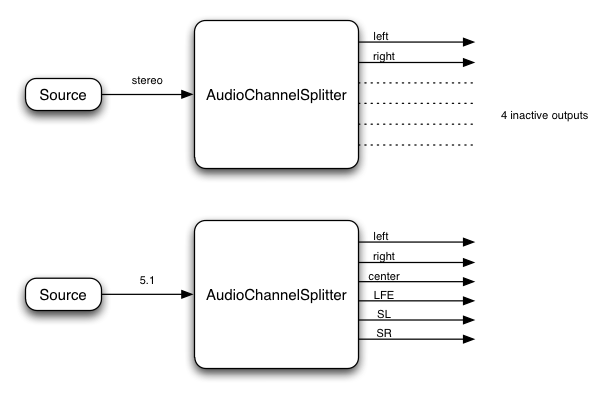
ChannelSplitterNode インターフェース 原文
ChannelSplitterNode は高度なアプリケーションで、 ChannelMergerNode
numberOfInputs : 1
numberOfOutputs : Variable N (defaults to 6) // number of "active" (non-silent) outputs is determined by number of channels in the input
channelCountMode = "max";
channelInterpretation = "speakers";
このインターフェースはルーティンググラフ中のオーディオストリームの個別のチャンネルにアクセスする AudioNodeChannelSplitterNodeAudioContext
createChannelSplitter() の numberOfOutputs パラメータで決まります) があり、 この値が渡されない場合のデフォルトの数は 6 になります。 "アクティブ"でないどの出力も無音を出力し、通常はどこにも接続されません。
例:
Fig. 6
チャンネルスプリッターの構成図
この例ではスプリッターはチャンネルの(例えば左チャンネル、右チャンネルなどの)識別はせず 、単純に入力チャンネルの順序に従って出力チャンネルを分割する事に注意してください。
ChannelSplitterNode を使うアプリケーションの1つは個別のチャンネルのゲインの制御を必要とする "マトリックス・ミキシング" を行うものです。
interface ChannelSplitterNode : AudioNode
2.25
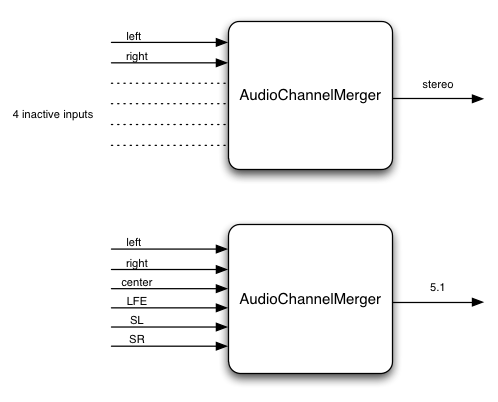
ChannelMergerNode インターフェース 原文
ChannelMergerNodeChannelSplitterNode
numberOfInputs : Variable N (default to 6)
numberOfOutputs : 1
channelCount = 1;
channelCountMode = "explicit";
channelInterpretation = "speakers";
このインターフェースは複数のオーディオストリームからチャンネルを結合して1つのオーディオストリームにする AudioNode
複数の入力を1つの出力にまとめる時、それぞれの入力は指定のミキシングルールによって1チャンネル(モノ)にダウンミックスされます。
接続されていない入力も1チャンネルの無音 としてカウントされて出力されます。
入力ストリームを変える事は出力のチャンネルの順序に影響しません。
ChannelMergerNodechannelCount および channelCountMode を変更する事はできません。変更しようとした場合、InvalidState 例外を発生します (MUST )。
例:
例えば、デフォルトの ChannelMergerNode
また、ChannelMergerNode
図. 7
チャンネルマージャーの構成図
interface ChannelMergerNode : AudioNode
2.26
DynamicsCompressorNode インターフェース 原文
DynamicsCompressorNodeAudioNode
ダイナミック・コンプレッションは音楽制作やゲーム・オーディオで非常に良く使用されるものです。
これは信号の音量が大きな部分を抑え、音量が小さな部分を持ち上げます。
全体として、より大きく、豊かで隙間のない音を作る事ができます。
これは特に、多くの個別サウンドを同時に再生するゲームと音楽アプリケーションで、全体の信号レベルを制御してスピーカーへの出力のクリッピング(歪み)を避けるために重要です。
numberOfInputs : 1
numberOfOutputs : 1
channelCount = 2;
channelCountMode = "explicit";
channelInterpretation = "speakers";
interface DynamicsCompressorNode : AudioNode readonly attribute AudioParamthreshold
readonly attribute AudioParamknee
readonly attribute AudioParamratio
readonly attribute float reduction
readonly attribute AudioParamattack
readonly attribute AudioParamrelease
}; 2.26.1 属性 原文 attack AudioParam
ゲインを 10dB 減衰させるために必要な時間 (秒) です。 これは名目上 0 から 1 の範囲を持ち、デフォルトの value は 0.003 です。
knee AudioParam
threadhold を超えた部分の範囲を表すデシベル値で、この範囲ではカーブが "ratio" まで滑らかに変化します。 このデフォルトの value は 0 から 40 の範囲中、 30 になっています。
ratio AudioParam
出力が 1dB 変化するための入力の dB の変化量です。 このデフォルトの value は、 1 から 20 の範囲中 12 になっています。
reduction float 型, readonly
メーターの表示のために使用するリードオンリーのデシベル値で、信号に対するコンプレッサーの動作による、現在のゲインの減衰量を表します。
もし信号が供給されていない場合この値は 0 (ゲイン減衰なし)になります。
release AudioParam
ゲインを 10dB 増加させるために必要な時間 (秒) です。 これは名目上 0 から 1 の範囲を持ち、デフォルトの value は 0.250 です。
threshold AudioParam
これを超えた時にコンプレッション動作を開始するデシベル値です。 デフォルトの value は -100 から 0 の範囲中、 -24 になっています。
2.27
BiquadFilterNode インターフェース 原文
BiquadFilterNodeAudioNode
低次フィルタは基本的なトーンコントロール(バス、ミドル、トレブル)やグラフィックイコライザーやより高度なフィルタを構成するブロックです。 複数の BiquadFilterNodefrequencyBiquadFilterNode"lowpass" です。
frequencydetunea-rate パラメータで computedFrequency の値を決定するために一緒に使用されます:
computedFrequency ( t ) = frequency ( t ) * pow ( 2 , detune ( t ) / 1200 ) numberOfInputs : 1
numberOfOutputs : 1
channelCountMode = "max";
channelInterpretation = "speakers";
出力のチャンネル数は常に入力のチャンネル数と同じになります。
enum BiquadFilterType {
"lowpass ",
"highpass ",
"bandpass ",
"lowshelf ",
"highshelf ",
"peaking ",
"notch ",
"allpass "
}; 列挙値の説明 lowpass
ローパスフィルタ は カットオフ周波数より低い周波数をそのまま通し、カットオフよりも高い周波数を減衰させます。これは標準的な2次の レゾナントローパスフィルタの実装で、 12dB/オクターブ のロールオフを持ちます。
frequency
カットオフ周波数です。
Q
カットオフ周波数にどれだけピークを付けて共振させるかを制御します。 大きな値はより強く共振させます。 このフィルタタイプではこの値は伝統的な従来の Q ではなく、デシベルで表される共振の値である事に注意してください。
gain
このフィルタのタイプでは使用しません。
highpass
ハイパスフィルタ はローパスフィルタの反対の機能を持ちます。 カットオフ周波数よりも高い周波数をそのまま通し、カットオフよりも低い周波数を減衰させます。 これは標準的な2次レゾナントハイパスフィルタの実装で、 12dB/オクターブ のロールオフを持ちます。
frequency
これより低い周波数を減衰させるカットオフ周波数です。
Q
カットオフ周波数にどれだけピークを付けて共振させるかを制御します。 大きな値はより強く共振させます。 このフィルタタイプではこの値は伝統的な従来の Q ではなく、デシベルで表される共振の値である事に注意してください。
gain
このフィルタのタイプでは使用しません。
bandpass
バンドパスフィルタ はある範囲の周波数をそのまま通し、この周波数範囲より上または下の周波数を減衰させます。 これは2次のバンドパスフィルタを実装しています。
frequency
周波数範囲の中心周波数です。
Q
周波数範囲の幅を制御します。この幅は Q の値が増加すると狭くなります。
gain
このフィルタのタイプでは使用しません。
lowshelf
ローシェルフフィルタは全ての周波数を通しますが、低い周波数だけを増幅(または減衰)させます。 これは2次のローシェルフフィルタを実装しています。
frequency
増幅(または減衰)させる上限の周波数です。
Q
このフィルタのタイプでは使用しません。
gain
dB で表した増幅率です。もしこの値が負ならばその周波数は減衰されます。
highshelf
ハイシェルフフィルタはローシェルフフィルタとは反対に、すべての周波数を通しますが高い周波数だけを増幅します。 これは2次のハイシェルフフィルタを実装しています。
frequency
増幅(または減衰)させる下限の周波数です。
Q
このフィルタのタイプでは使用しません。
gain
dB で表した増幅率です。もしこの値が負ならばその周波数は減衰されます。
peaking
ピーキングフィルタは全ての周波数を通しますが、ある周波数の範囲だけが増幅(または減衰)されます。
frequency
増幅される中心の周波数です。
Q
増幅される周波数の幅を制御します。値が大きいと幅は狭くなります。
gain
dB で表した増幅率です。もしこの値が負ならばその周波数は減衰されます。
notch
ノッチフィルタ (バンドストップまたはバンドリジェクション・フィルタ とも呼ばれます) は、バンドパスフィルタの逆の機能です。 ある周波数を除く全ての周波数を通します。
frequency
ノッチを適用する中心の周波数です。
Q
減衰させる周波数の幅を制御します。大きな値は幅が狭い事を意味します。
gain
このフィルタのタイプでは使用しません。
allpass
オールパスフィルタ は全ての周波数を通しますが、周波数の変化に対して位相が変化します。 これは2次のオールパスフィルタを実装しています。
frequency
位相変化が発生する中心の周波数です。別の見方では群遅延 が最大になる周波数です。
Q
中心周波数での位相変化がどれくらい急峻であるかを制御します。値が大きいと、より急峻な位相変化で大きな群遅延である事を意味します。
gain
このフィルタのタイプでは使用しません。
BiquadFilterNodea-rate の AudioParam
interface BiquadFilterNode : AudioNode attribute BiquadFilterTypetype
readonly attribute AudioParamfrequency
readonly attribute AudioParamdetune
readonly attribute AudioParamQ
readonly attribute AudioParamgain
void getFrequencyResponse Float32Array frequencyHz Float32Array magResponse Float32Array phaseResponse
}; 2.27.2 メソッド 原文 getFrequencyResponse
現在のフィルタパラメータの設定から指定の周波数に対する応答特性を計算します。
3 つのパラメータは同じ長さの Float32Array でなくてはなりません (MUST )。そうでない場合は InvalidAccessError 例外を発生します (MUST )。
周波数応答は、現在の処理ブロックに対応した AudioParamMUST )。
パラメータ 型 Null可 省略可 説明 frequencyHz Float32Array✘ ✘
このパラメータは応答特性を計算する周波数の配列を指定します。
magResponse Float32Array✘ ✘
パラメータはリニア振幅特性の値を受け取る配列を指定します。
もし frequencyHz パラメータが [0; sampleRate/2] の範囲にない場合 (ここで sampleRate は AudioContextsampleRatemagResponse 配列の同じインデックスには NaN が格納されなくてはなりません (MUST )。
phaseResponse Float32Array✘ ✘
パラメータはラジアン単位の位相特性を受け取る配列を指定します。
もし frequencyHz パラメータが [0; sampleRate/2] の範囲にない場合 (ここで sampleRate は AudioContextsampleRatephaseResponse 配列の同じインデックスには NaN が格納されなくてはなりません (MUST )。
戻り値: void
2.27.3
フィルター特性 原文
BiquadFilterNode「準拠した実装」 が実装すべきフィルターについて記述しています (MUST )。これらの式はAudio EQ Cookbook で見られる式を基にしています。
BiquadFilterNode
$$
H(z) = \frac{\frac{b_0}{a_0} + \frac{b_1}{a_0}z^{-1} + \frac{b_2}{a_0}z^{-2}}
{1+\frac{a_1}{a_0}z^{-1}+\frac{a_2}{a_0}z^{-2}}
$$
フィルターの初期状態は 0 です。
上記の伝達関数内の係数はそれぞれのノードタイプによって異なります。
BiquadFilterNodeAudioParamcomputedValue に基づいて次の中間変数が計算のために必要になります。
各フィルタータイプに対応する 6 つの係数 (\(b_0, b_1, b_2, a_0, a_1, a_2\)) は:
lowpass
$$
\begin{align*}
b_0 &= \frac{1 - \cos\omega_0}{2} \\
b_1 &= 1 - \cos\omega_0 \\
b_2 &= \frac{1 - \cos\omega_0}{2} \\
a_0 &= 1 + \alpha_B \\
a_1 &= -2 \cos\omega_0 \\
a_2 &= 1 - \alpha_B
\end{align*}
$$
highpass
$$
\begin{align*}
b_0 &= \frac{1 + \cos\omega_0}{2} \\
b_1 &= -(1 + \cos\omega_0) \\
b_2 &= \frac{1 + \cos\omega_0}{2} \\
a_0 &= 1 + \alpha_B \\
a_1 &= -2 \cos\omega_0 \\
a_2 &= 1 - \alpha_B
\end{align*}
$$
bandpass
$$
\begin{align*}
b_0 &= \alpha_Q \\
b_1 &= 0 \\
b_2 &= -\alpha_Q \\
a_0 &= 1 + \alpha_Q \\
a_1 &= -2 \cos\omega_0 \\
a_2 &= 1 - \alpha_Q
\end{align*}
$$
notch
$$
\begin{align*}
b_0 &= 1 \\
b_1 &= -2\cos\omega_0 \\
b_2 &= 1 \\
a_0 &= 1 + \alpha_Q \\
a_1 &= -2 \cos\omega_0 \\
a_2 &= 1 - \alpha_Q
\end{align*}
$$
allpass
$$
\begin{align*}
b_0 &= 1 - \alpha_Q \\
b_1 &= -2\cos\omega_0 \\
b_2 &= 1 + \alpha_Q \\
a_0 &= 1 + \alpha_Q \\
a_1 &= -2 \cos\omega_0 \\
a_2 &= 1 - \alpha_Q
\end{align*}
$$
peaking
$$
\begin{align*}
b_0 &= 1 + \alpha_Q\, A \\
b_1 &= -2\cos\omega_0 \\
b_2 &= 1 - \alpha_Q\,A \\
a_0 &= 1 + \frac{\alpha_Q}{A} \\
a_1 &= -2 \cos\omega_0 \\
a_2 &= 1 - \frac{\alpha_Q}{A}
\end{align*}
$$
lowshelf
$$
\begin{align*}
b_0 &= A \left[ (A+1) - (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A})\right] \\
b_1 &= 2 A \left[ (A-1) - (A+1) \cos\omega_0 )\right] \\
b_2 &= A \left[ (A+1) - (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A}) \right] \\
a_0 &= (A+1) + (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A} \\
a_1 &= -2 \left[ (A-1) + (A+1) \cos\omega_0\right] \\
a_2 &= (A+1) + (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A})
\end{align*}
$$
highshelf
$$
\begin{align*}
b_0 &= A\left[ (A+1) + (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} )\right] \\
b_1 &= -2A\left[ (A-1) + (A+1)\cos\omega_0 )\right] \\
b_2 &= A\left[ (A+1) + (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A} )\right] \\
a_0 &= (A+1) - (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} \\
a_1 &= 2\left[ (A-1) - (A+1)\cos\omega_0\right] \\
a_2 &= (A+1) - (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A}
\end{align*}
$$
2.28
IIRFilterNode インターフェース 原文
IIRFilterNodeAudioNodeBiquadFilterNode
一般的に数値問題に関して敏感ではありません
フィルターのパラメータがオートメーションできます
全ての偶数次 IIR フィルターの作成に使用できます
しかしながら奇数次フィルターは作成できないため、もしそのようなフィルターが必要でオートメーションが不要ならば IIR フィルターが適切かもしれません。
一度作成された後、 IIR フィルターの係数は変更する事ができません。
numberOfInputs : 1
numberOfOutputs : 1
channelCountMode = "max";
channelInterpretation = "speakers";
出力のチャンネル数は常に入力のチャンネル数と同じになります。
interface IIRFilterNode : AudioNode void getFrequencyResponse Float32Array frequencyHz Float32Array magResponse Float32Array phaseResponse
}; 2.28.1 メソッド 原文 getFrequencyResponse
与えられた現在のフィルターの設定で、指定の周波数における周波数応答を計算します。
Parameter Type Nullable 省略可 Description frequencyHz Float32Array✘ ✘
このパラメータは応答を計算する周波数の配列を指定します。
magResponse Float32Array✘ ✘
このパラメータはリニア振幅応答の出力結果を受け取る配列を指定します。
もしこの配列が frequencyHz よりも小さい場合、NotSupportedError 例外を発生します (MUST )。
phaseResponse Float32Array✘ ✘
このパラメータはラジアンでの位相応答の出力結果を受け取る配列を指定します。
もしこの配列が frequencyHz よりも小さい場合、NotSupportedError 例外を発生します (MUST )。
戻り値: void
2.28.2
Filter 定義 原文
createIIRFilterで指定される feedforward 係数を\(b_m\)、
feedback を\(a_n\)とします。
すると一般的な IIR フィルターの 伝達関数は次のように与えられます
$$
H(z) = \frac{\sum_{m=0}^{M} b_m z^{-m}}{\sum_{n=0}^{N} a_n z^{-n}}
$$
ここで、\(M + 1\) は \(b\) 配列の長さで、 \(N + 1\) は \(a\) 配列の長さです。
係数 \(a_0\) は 0 にはできません。
少なくとも1つの \(b_m\) が非0 でなくてはなりません。
同じように、時間領域の式については:
$$
\sum_{k=0}^{N} a_k y(n-k) = \sum_{k=0}^{M} b_k x(n-k)
$$
フィルターの初期状態は全て 0 になっています。
2.29
WaveShaperNode インターフェース 原文
WaveShaperNodeAudioNode
非線形ウェーブシェイピング歪みは微妙な非線形ウォーミングやはっきりしたディストーションの両方のエフェクトで一般的に使用されています。 任意の非線形シェイピング曲線を指定する事ができます
numberOfInputs : 1
numberOfOutputs : 1
channelCountMode = "max";
channelInterpretation = "speakers";
出力のチャンネル数は常に入力のチャンネル数に同じです。
列挙値の説明 none
オーバーサンプリングを行いません
2x
2 倍オーバーサンプリングを行います
4x
4 倍オーバーサンプリングを行います
enum OverSampleType {
"none ",
"2x ",
"4x "
}; WaveShaperNode : AudioNode attribute Float32Array? curve
attribute OverSampleTypeoversample
};2.29.1 属性 原文 curve Float32Array 型, nullable
ウェーブシェイピング・エフェクトで使用されるシェイピング曲線です。 入力信号は名目上 [-1 ; +1] の範囲になります。 この範囲内のそれぞれの入力サンプルはシェイピング曲線にインデックスされ、信号レベル0が配列の要素が奇数個の場合は中央の値、そうでなく要素が偶数個の場合はもっとも中心に近い2つの値が補間された値になります。
-1よりも小さい全てのサンプルは曲線配列の最初の値に対応します。 +1よりも大きい全てのサンプルは曲線配列の最後の値に対応します。
実装は曲線の配列の隣接した値から直線補間を行わなくてはなりません。
curve 属性の初期値はnullで、これは WaveShaperNode は入力を変更せずにそのまま出力する事を意味します。
曲線の値は [-1; 1] の範囲に広がっています。
これは curve の値が偶数個の場合は信号 0 に対応する値を持っていない事を意味し、curve が奇数個の値の場合は信号 0 に対応する値を持っている事を意味します。
もしこの属性が長さが 2 より小さい Float32Array に設定されると
InvalidStateError 例外を発生します (MUST )。
この属性が設定された時、WaveShaperNode
oversample OverSampleType
シェイピング曲線に(行うならば)どのようなオーバーサンプリングを行うかを指定します。
デフォルト値は "none" で、曲線は直接入力サンプルに適用される事を意味します。
値、"2x" または "4x" は幾らかのエイリアシングを避けて処理の品質を向上させ、"4x" が最も良い品質となります。
アプリケーションによっては非常に高精度なシェイピング曲線を得るためにオーバーサンプリングを使用しない方が良い場合もあります。
"2x" または "4x" の値は次のステップを実行しなくてはならない事を意味します:
入力のサンプルを AudioContext
シェイピング曲線を適用します。
結果を AudioContext
正確なアップサンプリングおよびダウンサンプリングフィルターは定められておらず、(低エイリアシング等の)音の品質、低レイテンシー、パフォーマンス等をチューニングする事もできます。
2.30
OscillatorNode インターフェース 原文
OscillatorNodePeriodicWave
オシレータは音の合成において一般的な基本構成ブロックです。
OscillatorNode は start() メソッドで指定された時刻に音の発生を開始します。
数学的に言えば、連続した時間 の周期波形は周波数領域で考えた場合、非常に高い (あるいは無限に高い) 周波数情報を持つ事ができます。
この波形があるサンプルレートの離散時間のデジタルオーディオ信号としてサンプリングされる場合、波形をデジタル化する前にナイキスト 周波数 (サンプリング周波数の半分) よりも高い高周波数成分の除去 (フィルタで取り除く事) を考慮しなくてはなりません。 これを行わない場合、 (ナイキスト周波数よりも) 高い周波数のエイリアス がナイキスト周波数よりも低い周波数に鏡像として折り返されます。
多くの場合、これは音として聴こえる好ましくないノイズを引き起こします。
これはオーディオ DSP における基本的で良く知られている原理です。
このエイリアスを避けるため、実装に使う事のできる幾つかの実践的な手段があります。
しかしこれらの手段によらず、理想的 な離散時間のデジタルオーディオ信号は数学的には完全に定義されます。
( CPU の負荷という意味で) 実装のコスト対、理想への忠実性というトレードオフが実装上の問題になります。
実装はこの理想を達成するためにいくらかの考慮をする事が期待されますが、ローエンド・ハードウェアでは低品質ローコストな手段を考慮する事も合理的です。
.frequency と .detune はどちらも a-rate パラメータで、 computedFrequency の値を決定するために一緒に使われます:
computedFrequency ( t ) = frequency ( t ) * pow ( 2 , detune ( t ) / 1200 )
OscillatorNode の各時刻での瞬間的な位相は computedFrequency を時間で積分したものになります。
numberOfInputs : 0
numberOfOutputs : 1 (mono output)
enum OscillatorType {
"sine ",
"square ",
"sawtooth ",
"triangle ",
"custom "
}; 列挙値の説明 sine
サイン波
square
デューティ比 0.5 の矩形波
sawtooth
鋸歯状波
triangle
三角波
custom
カスタム周期波形
interface OscillatorNode : AudioNode attribute OscillatorTypetype
readonly attribute AudioParamfrequency
readonly attribute AudioParamdetune
void start optional double when = 0 );
void stop optional double when = 0 );
void setPeriodicWave PeriodicWaveperiodicWave
attribute EventHandler onended
}; 2.30.1 属性 原文 detune AudioParam
(セントで表される) デチューン値で、これは frequency を与えられた量だけオフセットします。 デフォルトの value は 0 です。 このパラメータは a-rate です。
frequency AudioParam
(Hz:ヘルツで表される) 周期波形の周波数で、そのデフォルトの value は 440 です。このパラメータは a-rate です。
onended EventHandler 型
OscillatorNode
HTML HTML EventHandler を設定するために使われる属性です。 OscillatorNodeHTML HTML Event が イベントハンドラにディスパッチされます。
type OscillatorType
周期波形の形状です。 "custom" 以外の波形の定数値は直接設定する事ができます。(訳注: "custom" を直接設定しようとすると )そうすると InvalidStateError 例外を発生します (MUST )。
カスタム波形を設定するには
setPeriodicWave() メソッドを使用する事ができ、それによってこの属性は "custom" に設定されます。
デフォルト値は "sine" です。属性が設定された時、オシレータの位相は保存されなくてはなりません (MUST )。
2.31
PeriodicWave インターフェース 原文
PeriodicWave は OscillatorNode
setPeriodicWave() を参照してください。
interface PeriodicWave {
};
2.31.1
PeriodicWaveConstraints 原文
PeriodicWaveConstraints ディクショナリは波形が正規化されるかどうかを指定するために使用されます。
dictionary PeriodicWaveConstraints {
boolean disableNormalization false ;
}; disableNormalization boolean 型, デフォルト値は false
周期波形が正規化されるかどうかを制御します。もし true ならば波形は正規化されません。そうでなければ波形は正規化されます。
2.31.4
オシレータ係数 原文
組み込み済みのオシレータタイプは PeriodicWave
次の記述において、 \(a\) は createPeriodicWave() で使用するリアル係数の配列で \(b\) はイマジナリ係数の配列です。
全てのケースで波形は奇関数のため、全ての \(n\) に対して \(a[n] = 0\) となります。
また、全てのケースで \(b[0] = 0\) です。そのため、 \(n \ge 1\) の \(b[n]\) だけが以下に規定されています。
"sine"
$$
b[n] = \begin{cases}
1 & \mbox{for } n = 1 \\
0 & \mbox{otherwise}
\end{cases}
$$
"square"
$$
b[n] = \frac{2}{n\pi}\left[1 - (-1)^n\right]
$$
"sawtooth"
$$
b[n] = (-1)^{n+1} \dfrac{2}{n\pi}
$$
"triangle"
$$
b[n] = \frac{8\sin\dfrac{n\pi}{2}}{(\pi n)^2}
$$
このインターフェースは MediaStream からのオーディオソースを表します。 MediaStream からの最初の AudioMediaStreamTrack がオーディオソースとして使用されます。
これらのインターフェースは [mediacapture-streams
numberOfInputs : 0
numberOfOutputs : 1
出力のチャンネル数は、AudioMediaStreamTrack のチャンネル数に対応します。 もし有効なオーディオトラックがない場合、1 チャンネルの無音が出力されます。
interface MediaStreamAudioSourceNode : AudioNode
12.
承認 原文
この仕様は W3C Audio Working Group の集合著作物です。
Members of the Working Group are (at the time of writing, and by
alphabetical order):W3C Staff); Lowis, Chris (Invited Expert. WG co-chair from December
2012 to September 2013, affiliated with British Broadcasting
Corporation); Mandyam, Giridhar (Qualcomm Innovation Center, Inc);
Noble, Jer (Apple, Inc.); O'Callahan, Robert(Mozilla Foundation);
Onumonu, Anthony (British Broadcasting Corporation); Paradis, Matthew
(British Broadcasting Corporation); Raman, T.V. (Google, Inc.);
Schepers, Doug (W3C /MIT ); Shires, Glen (Google, Inc.); Smith, Michael
(W3C /Keio); Thereaux, Olivier (British Broadcasting Corporation); Toy,
Raymond (Google, Inc.); Verdie, Jean-Charles (MStar Semiconductor,
Inc.); Wilson, Chris (Google,Inc.) - Specification Co-editor; ZERGAOUI,
Mohamed (INNOVIMAX)
Former members of the Working Group and contributors to the
specification include:W3C Invited Experts) — WG co-chair
from March 2011 to July 2012; Michel, Thierry (W3C /ERCIM ); Rogers,
Chris (Google, Inc.) – Specification Editor until August 2013; Wei,
James (Intel Corporation);